SCIENTIFIC COMPUTING AND IMAGING INSTITUTEat the University of Utah
An internationally recognized leader in visualization, scientific computing, and image analysis
SCI Publications
2016
Embedded Domain-Specific Language and Runtime System for Progressive Spatiotemporal Data Analysis and Visualization
C. Christensen, S. Liu, G. Scorzelli, J. Lee, P.-T. Bremer, V. Pascucci.
“Embedded Domain-Specific Language and Runtime System for Progressive Spatiotemporal Data Analysis and Visualization,” In Symposium on Large Data Analysis and Visualization, IEEE, 2016.
ABSTRACT
As our ability to generate large and complex datasets grows, accessing and processing these massive data collections is increasingly the primary bottleneck in scientific analysis. Challenges include retrieving, converting, resampling, and combining remote and often disparately located data ensembles with only limited support from existing tools. In particular, existing solutions rely predominantly on extensive data transfers or large-scale remote computing resources, both of which are inherently offline processes with long delays and substantial repercussions for any mistakes. Such workflows severely limit the flexible exploration and rapid evaluation of new hypotheses that are crucial to the scientific process and thereby impede scientific discovery. Here we present an embedded domain-specific language (EDSL) specifically designed for the interactive exploration of largescale, remote data. Our EDSL allows users to express a wide range of data analysis operations in a simple and abstract manner. The underlying runtime system transparently resolves issues such as remote data access and resampling while at the same time maintaining interactivity through progressive and interruptible computation. This system enables, for the first time, interactive remote exploration of massive datasets such as the 7km NASA GEOS-5 Nature Run simulation, which previously have been analyzed only offline or at reduced resolution.
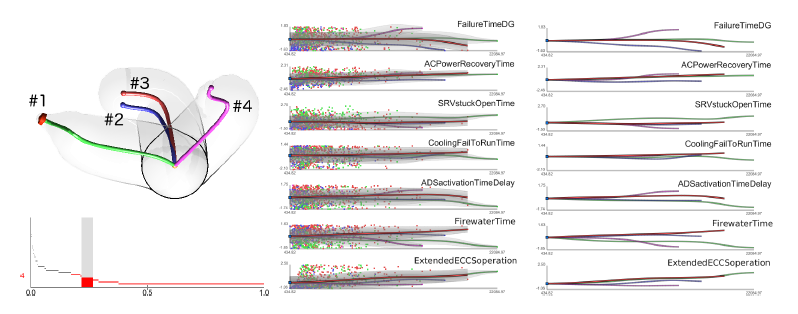
Analyzing Simulation-Based PRA Data Through Traditional and Topological Clustering: A BWR Station Blackout Case Study
D. Maljovec, S. Liu, Bei Wang, V. Pascucci, P. T. Bremer, D. Mandelli, C. Smith..
“Analyzing Simulation-Based PRA Data Through Traditional and Topological Clustering: A BWR Station Blackout Case Study,” In Reliability Engineering & System Safety, Vol. 145, Elsevier, pp. 262--276. January, 2016.
DOI: 10.1016/j.ress.2015.07.001
ABSTRACT
×
Dynamic probabilistic risk assessment (DPRA) methodologies couple system simulator codes (e.g., RELAP, MELCOR) with simulation controller codes (e.g., RAVEN, ADAPT). Whereas system simulator codes model system dynamics deterministically, simulation controller codes introduce both deterministic (e.g., system control logic, operating procedures) and stochastic (e.g., component failures, parameter uncertainties) elements into the simulation. Typically, a DPRA is performed by sampling values of a set of parameters, and simulating the system behavior for that specific set of parameter values. For complex systems, a major challenge in using DPRA methodologies is to analyze the large number of scenarios generated, where clustering techniques are typically employed to better organize and interpret the data. In this paper, we focus on the analysis of two nuclear simulation datasets that are part of the risk-informed safety margin characterization (RISMC) boiling water reactor (BWR) station blackout (SBO) case study. We provide the domain experts a software tool that encodes traditional and topological clustering techniques within an interactive analysis and visualization environment, for understanding the structures of such high-dimensional nuclear simulation datasets. We demonstrate through our case study that both types of clustering techniques complement each other in bringing enhanced structural understanding of the data.
Evaluation of in-situ analysis strategies at scale for power efficiency and scalability
I. Rodero, M. Parashar, A.G. Landge, S. Kumar, V. Pascucci,, P.T. Bremer.
“Evaluation of in-situ analysis strategies at scale for power efficiency and scalability,” In Cluster, Cloud and Grid Computing (CCGrid), 2016 16th IEEE/ACM International Symposium on, IEEE, pp. 156--164. 2016.
ABSTRACT
The increasing gap between available compute power and I/O capabilities is resulting in simulation pipelines running on leadership computing facilities being reformulated. In particular, in-situ processing is complementing conventional post-process analysis; however, it can be performed by using the same compute resources as the simulation or using secondary dedicated resources.
In this paper, we focus on three different in-situ analysis strategies, which use the same compute resources as the ongoing simulation but different data movement strategies. We evaluate the costs incurred by these strategies in terms of run time, scalability and power/energy consumption. Furthermore, we extrapolate power behavior to peta-scale and investigate different design choices through projections. Experimental evaluation at full machine scale on Titan supports that using fewer cores per node for in-situ analysis is the optimum choice in terms of scalability. Hence, further research effort should be devoted towards developing in-situ analysis techniques following this strategy in future high-end systems.
2015
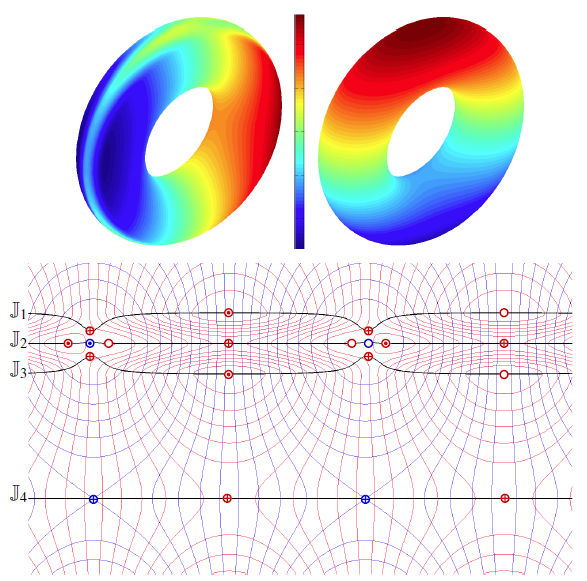
Local, Smooth, and Consistent Jacobi Set Simplification
H. Bhatia, Bei Wang, G. Norgard, V. Pascucci, P. T. Bremer.
“Local, Smooth, and Consistent Jacobi Set Simplification,” In Computational Geometry, Vol. 48, No. 4, Elsevier, pp. 311-332. May, 2015.
DOI: 10.1016/j.comgeo.2014.10.009
ABSTRACT
×
The relation between two Morse functions defined on a smooth, compact, and orientable 2-manifold can be studied in terms of their Jacobi set. The Jacobi set contains points in the domain where the gradients of the two functions are aligned. Both the Jacobi set itself as well as the segmentation of the domain it induces, have shown to be useful in various applications. In practice, unfortunately, functions often contain noise and discretization artifacts, causing their Jacobi set to become unmanageably large and complex. Although there exist techniques to simplify Jacobi sets, they are unsuitable for most applications as they lack fine-grained control over the process, and heavily restrict the type of simplifications possible.
This paper introduces the theoretical foundations of a new simplification framework for Jacobi sets. We present a new interpretation of Jacobi set simplification based on the perspective of domain segmentation. Generalizing the cancellation of critical points from scalar functions to Jacobi sets, we focus on simplifications that can be realized by smooth approximations of the corresponding functions, and show how these cancellations imply simultaneous simplification of contiguous subsets of the Jacobi set. Using these extended cancellations as atomic operations, we introduce an algorithm to successively cancel subsets of the Jacobi set with minimal modifications to some userdefined metric. We show that for simply connected domains, our algorithm reduces a given Jacobi set to its minimal configuration, that is, one with no birth-death points (a birth-death point is a specific type of singularity within the Jacobi set where the level sets of the two functions and the Jacobi set have a common normal direction).
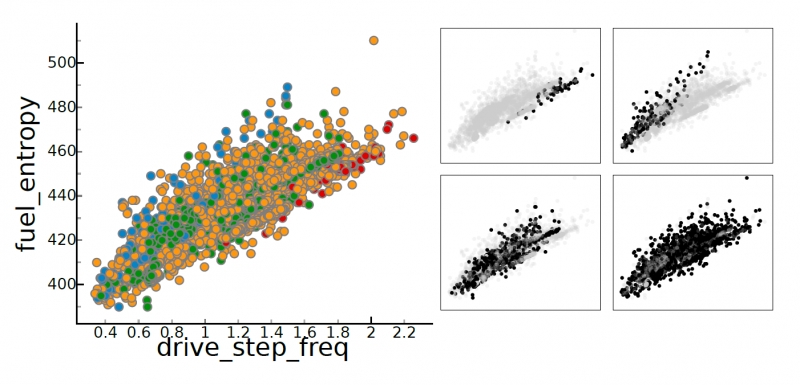
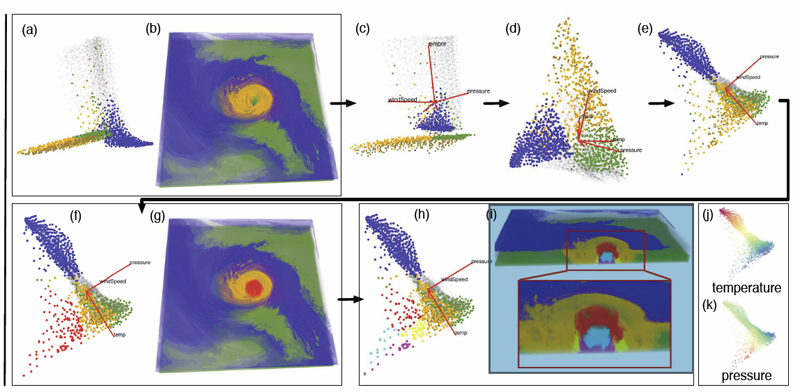
ND2AV: N-Dimensional Data Analysis and Visualization -- Analysis for the National Ignition Campaign
P. T. Bremer, D. Maljovec, A. Saha, Bei Wang, J. Gaffney, B. K. Spears, V. Pascucci.
“ND2AV: N-Dimensional Data Analysis and Visualization -- Analysis for the National Ignition Campaign,” In Computing and Visualization in Science, 2015.
ABSTRACT
×
One of the biggest challenges in high-energy physics is to analyze a complex mix of experimental and simulation data to gain new insights into the underlying physics. Currently, this analysis relies primarily on the intuition of trained experts often using nothing more sophisticated than default scatter plots. Many advanced analysis techniques are not easily accessible to scientists and not flexible enough to explore the potentially interesting hypotheses in an intuitive manner. Furthermore, results from individual techniques are often difficult to integrate, leading to a confusing patchwork of analysis snippets too cumbersome for data exploration. This paper presents a case study on how a combination of techniques from statistics, machine learning, topology, and visualization can have a significant impact in the field of inertial confinement fusion. We present the ND2AV: N-Dimensional Data Analysis and Visualization framework, a user-friendly tool aimed at exploiting the intuition and current work flow of the target users. The system integrates traditional analysis approaches such as dimension reduction and clustering with state-of-the-art techniques such as neighborhood graphs and topological analysis, and custom capabilities such as defining combined metrics on the fly. All components are linked into an interactive environment that enables an intuitive exploration of a wide variety of hypotheses while relating the results to concepts familiar to the users, such as scatter plots. ND2AV uses a modular design providing easy extensibility and customization for different applications. ND2AV is being actively used in the National Ignition Campaign and has already led to a number of unexpected discoveries.
Morse-Smale Analysis of Ion Diffusion for DFT Battery Materials Simulations
Ab initio molecular dynamics (AIMD) simulations are increasingly useful in modeling, optimizing and synthesizing materials in energy sciences. In solving Schrodinger's equation, they generate the electronic structure of the simulated atoms as a scalar field. However, methods for analyzing these volume data are not yet common in molecular visualization. The Morse-Smale complex is a proven, versatile tool for topological analysis of scalar fields. In this paper, we apply the discrete Morse-Smale complex to analysis of first-principles battery materials simulations. We consider a carbon nanosphere structure used in battery materials research, and employ Morse-Smale decomposition to determine the possible lithium ion diffusion paths within that structure. Our approach is novel in that it uses the wavefunction itself as opposed distance fields, and that we analyze the 1-skeleton of the Morse-Smale complex to reconstruct our diffusion paths. Furthermore, it is the first application where specific motifs in the graph structure of the complete 1-skeleton define features, namely carbon rings with specific valence. We compare our analysis of DFT data with that of a distance field approximation, and discuss implications on larger classical molecular dynamics simulations.
Visualizing High-Dimensional Data: Advances in the Past Decade
S. Liu, D. Maljovec, Bei Wang, P. T. Bremer, V. Pascucci.
“Visualizing High-Dimensional Data: Advances in the Past Decade,” In State of The Art Report, Eurographics Conference on Visualization (EuroVis), 2015.
ABSTRACT
×
Massive simulations and arrays of sensing devices, in combination with increasing computing resources, have generated large, complex, high-dimensional datasets used to study phenomena across numerous fields of study. Visualization plays an important role in exploring such datasets. We provide a comprehensive survey of advances in high-dimensional data visualization over the past 15 years. We aim at providing actionable guidance for data practitioners to navigate through a modular view of the recent advances, allowing the creation of new visualizations along the enriched information visualization pipeline and identifying future opportunities for visualization research.
Visual Exploration of High-Dimensional Data through Subspace Analysis and Dynamic Projections
S. Liu, Bei Wang, J. J. Thiagarajan, P. T. Bremer, V. Pascucci.
“Visual Exploration of High-Dimensional Data through Subspace Analysis and Dynamic Projections,” In Computer Graphics Forum, Vol. 34, No. 3, Wiley-Blackwell, pp. 271--280. June, 2015.
DOI: 10.1111/cgf.12639
ABSTRACT
×
We introduce a novel interactive framework for visualizing and exploring high-dimensional datasets based on subspace analysis and dynamic projections. We assume the high-dimensional dataset can be represented by a mixture of low-dimensional linear subspaces with mixed dimensions, and provide a method to reliably estimate the intrinsic dimension and linear basis of each subspace extracted from the subspace clustering. Subsequently, we use these bases to define unique 2D linear projections as viewpoints from which to visualize the data. To understand the relationships among the different projections and to discover hidden patterns, we connect these projections through dynamic projections that create smooth animated transitions between pairs of projections. We introduce the view transition graph, which provides flexible navigation among these projections to facilitate an intuitive exploration. Finally, we provide detailed comparisons with related systems, and use real-world examples to demonstrate the novelty and usability of our proposed framework.
2014
Extracting Features from Time-Dependent Vector Fields Using Internal Reference Frames
H. Bhatia, V. Pascucci, R.M. Kirby, P.-T. Bremer.
“Extracting Features from Time-Dependent Vector Fields Using Internal Reference Frames,” In Computer Graphics Forum, Vol. 33, No. 3, pp. 21--30. June, 2014.
DOI: 10.1111/cgf.12358
ABSTRACT
×
Extracting features from complex, time-dependent flow fields remains a significant challenge despite substantial research efforts, especially because most flow features of interest are defined with respect to a given reference frame. Pathline-based techniques, such as the FTLE field, are complex to implement and resource intensive, whereas scalar transforms, such as λ2, often produce artifacts and require somewhat arbitrary thresholds. Both approaches aim to analyze the flow in a more suitable frame, yet neither technique explicitly constructs one.
This paper introduces a new data-driven technique to compute internal reference frames for large-scale complex flows. More general than uniformly moving frames, these frames can transform unsteady fields, which otherwise require substantial processing of resources, into a sequence of individual snapshots that can be analyzed using the large body of steady-flow analysis techniques. Our approach is simple, theoretically well-founded, and uses an embarrassingly parallel algorithm for structured as well as unstructured data. Using several case studies from fluid flow and turbulent combustion, we demonstrate that internal frames are distinguished, result in temporally coherent structures, and can extract well-known as well as notoriously elusive features one snapshot at a time.
Robust Detection of Singularities in Vector Fields
H. Bhatia, A. Gyulassy, H. Wang, P.-T. Bremer, V. Pascucci .
“Robust Detection of Singularities in Vector Fields,” In Topological Methods in Data Analysis and Visualization III, Mathematics and Visualization, Springer International Publishing, pp. 3--18. March, 2014.
DOI: 10.1007/978-3-319-04099-8_1
ABSTRACT
×
Recent advances in computational science enable the creation of massive datasets of ever increasing resolution and complexity. Dealing effectively with such data requires new analysis techniques that are provably robust and that generate reproducible results on any machine. In this context, combinatorial methods become particularly attractive, as they are not sensitive to numerical instabilities or the details of a particular implementation. We introduce a robust method for detecting singularities in vector fields. We establish, in combinatorial terms, necessary and sufficient conditions for the existence of a critical point in a cell of a simplicial mesh for a large class of interpolation functions. These conditions are entirely local and lead to a provably consistent and practical algorithm to identify cells containing singularities.
The Natural Helmholtz-Hodge Decomposition For Open-Boundary Flow Analysis
H. Bhatia, V. Pascucci, P.-T. Bremer.
“The Natural Helmholtz-Hodge Decomposition For Open-Boundary Flow Analysis,” In IEEE Transactions on Visualization and Computer Graphics (TVCG), Vol. 99, pp. 1566--1578. 2014.
DOI: 10.1109/TVCG.2014.2312012
ABSTRACT
×
The Helmholtz-Hodge decomposition (HHD) describes a flow as the sum of an incompressible, an irrotational, and a harmonic flow, and is a fundamental tool for simulation and analysis. Unfortunately, for bounded domains, the HHD is not uniquely defined, and traditionally, boundary conditions are imposed to obtain a unique solution. However, in general, the boundary conditions used during the simulation may not be known and many simulations use open boundary conditions. In these cases, the flow imposed by traditional boundary conditions may not be compatible with the given data, which leads to sometimes drastic artifacts and distortions in all three components, hence producing unphysical results. Instead, this paper proposes the natural HHD, which is defined by separating the flow into internal and external components. Using a completely data-driven approach, the proposed technique obtains uniqueness without assuming boundary conditions a priori. As a result, it enables a reliable and artifact-free analysis for flows with open boundaries or unknown boundary conditions. Furthermore, our approach computes the HHD on a point-wise basis in contrast to the existing global techniques, and thus supports computing inexpensive local approximations for any subset of the domain. Finally, the technique is easy to implement for a variety of spatial discretizations and interpolated fields in both two and three dimensions.
Fast Multi-Resolution Reads of Massive Simulation Datasets
S. Kumar, C. Christensen, P.-T. Bremer, E. Brugger, V. Pascucci, J. Schmidt, M. Berzins, H. Kolla, J. Chen, V. Vishwanath, P. Carns, R. Grout.
“Fast Multi-Resolution Reads of Massive Simulation Datasets,” In Proceedings of the International Supercomputing Conference ISC'14, Leipzig, Germany, June, 2014.
ABSTRACT
×
Today's massively parallel simulation code can produce output ranging up to many terabytes of data. Utilizing this data to support scientific inquiry requires analysis and visualization, yet the sheer size of the data makes it cumbersome or impossible to read without computational resources similar to the original simulation. We identify two broad classes of problems for reading data and present effective solutions for both. The first class of data reads depends on user requirements and available resources. Tasks such as visualization and user-guided analysis may be accomplished using only a subset of variables with restricted spatial extents at a reduced resolution. The other class of reads require full resolution multi-variate data to be loaded, for example to restart a simulation. We show that utilizing the hierarchical multi-resolution IDX data format enables scalable and efficient serial and parallel read access on a variety of hardware from supercomputers down to portable devices. We demonstrate interactive view-dependent visualization and analysis of massive scientific datasets using low-power commodity hardware, and we compare read performance with other parallel file formats for both full and partial resolution data.
Efficient I/O and storage of adaptive-resolution data
S. Kumar, J. Edwards, P.-T. Bremer, A. Knoll, C. Christensen, V. Vishwanath, P. Carns, J.A. Schmidt, V. Pascucci.
“Efficient I/O and storage of adaptive-resolution data,” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, pp. 413--423. 2014.
DOI: 10.1109/SC.2014.39
ABSTRACT
×
We present an efficient, flexible, adaptive-resolution I/O framework that is suitable for both uniform and Adaptive Mesh Refinement (AMR) simulations. In an AMR setting, current solutions typically represent each resolution level as an independent grid which often results in inefficient storage and performance. Our technique coalesces domain data into a unified, multiresolution representation with fast, spatially aggregated I/O. Furthermore, our framework easily extends to importance-driven storage of uniform grids, for example, by storing regions of interest at full resolution and nonessential regions at lower resolution for visualization or analysis. Our framework, which is an extension of the PIDX framework, achieves state of the art disk usage and I/O performance regardless of resolution of the data, regions of interest, and the number of processes that generated the data. We demonstrate the scalability and efficiency of our framework using the Uintah and S3D large-scale combustion codes on the Mira and Edison supercomputers.
In-situ feature extraction of large scale combustion simulations using segmented merge trees
A.G. Landge, V. Pascucci, A. Gyulassy, J.C. Bennett, H. Kolla, J. Chen, P.-T. Bremer.
“In-situ feature extraction of large scale combustion simulations using segmented merge trees,” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC 2014), New Orleans, Louisana, IEEE Press, Piscataway, NJ, USA pp. 1020--1031. 2014.
ISBN: 978-1-4799-5500-8
DOI: 10.1109/SC.2014.88
ABSTRACT
The ever increasing amount of data generated by scientific simulations coupled with system I/O constraints are fueling a need for in-situ analysis techniques. Of particular interest are approaches that produce reduced data representations while maintaining the ability to redefine, extract, and study features in a post-process to obtain scientific insights.
This paper presents two variants of in-situ feature extraction techniques using segmented merge trees, which encode a wide range of threshold based features. The first approach is a fast, low communication cost technique that generates an exact solution but has limited scalability. The second is a scalable, local approximation that nevertheless is guaranteed to correctly extract all features up to a predefined size. We demonstrate both variants using some of the largest combustion simulations available on leadership class supercomputers. Our approach allows state-of-the-art, feature-based analysis to be performed in-situ at significantly higher frequency than currently possible and with negligible impact on the overall simulation runtime.
Visual Exploration of High-Dimensional Data: Subspace Analysis through Dynamic Projections
Shusen Liu, Bei Wang, J.J. Thiagarajan, P.-T. Bremer, V. Pascucci.
“Visual Exploration of High-Dimensional Data: Subspace Analysis through Dynamic Projections,” SCI Technical Report, No. UUSCI-2014-003, SCI Institute, University of Utah, 2014.
ABSTRACT
Understanding high-dimensional data is rapidly becoming a central challenge in many areas of science and engineering. Most current techniques either rely on manifold learning based techniques which typically create a single embedding of the data or on subspace selection to find subsets of the original attributes that highlight the structure. However, the former creates a single, difficult-to-interpret view and assumes the data to be drawn from a single manifold, while the latter is limited to axis-aligned projections with restrictive viewing angles. Instead, we introduce ideas based on subspace clustering that can faithfully represent more complex data than the axis-aligned projections, yet do not assume the data to lie on a single manifold. In particular, subspace clustering assumes that the data can be represented by a union of low-dimensional subspaces, which can subsequently be used for analysis and visualization. In this paper, we introduce new techniques to reliably estimate both the intrinsic dimension and the linear basis of a mixture of subspaces extracted through subspace clustering. We show that the resulting bases represent the high-dimensional structures more reliably than traditional approaches. Subsequently, we use the bases to define different “viewpoints”, i.e., different projections onto pairs of basis vectors, from which to visualize the data. While more intuitive than non-linear projections, interpreting linear subspaces in terms of the original dimensions can still be challenging. To address this problem, we present new, animated transitions between different views to help the user navigate and explore the high-dimensional space. More specifically, we introduce the view transition graph which contains nodes for each subspace viewpoint and edges for potential transition between views. The transition graph enables users to explore both the structure within a subspace and the relations between different subspaces, for better understanding of the data. Using a number of case studies on well-know reference datasets, we demonstrate that the interactive exploration through such dynamic projections provides additional insights not readily available from existing tools.
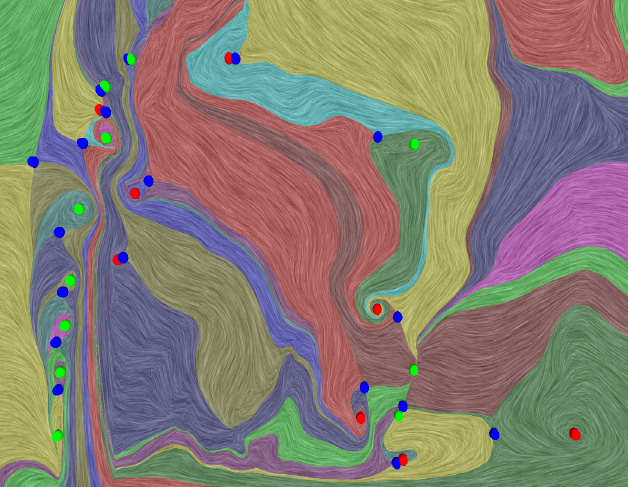
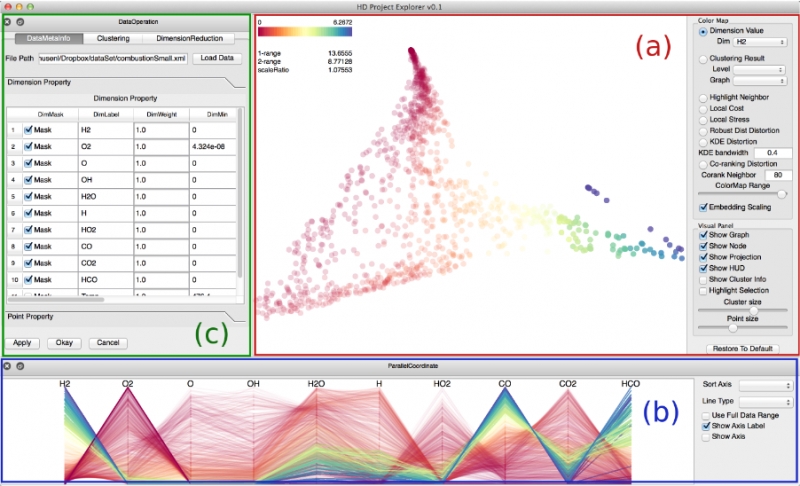
Distortion-Guided Structure-Driven Interactive Exploration of High-Dimensional Data
S. Liu, Bei Wang, P.-T. Bremer, V. Pascucci.
“Distortion-Guided Structure-Driven Interactive Exploration of High-Dimensional Data,” In Computer Graphics Forum, Vol. 33, No. 3, Wiley-Blackwell, pp. 101--110. June, 2014.
ABSTRACT
×
Dimension reduction techniques are essential for feature selection and feature extraction of complex high-dimensional data. These techniques, which construct low-dimensional representations of data, are typically geometrically motivated, computationally efficient and approximately preserve certain structural properties of the data. However, they are often used as black box solutions in data exploration and their results can be difficult to interpret. To assess the quality of these results, quality measures, such as co-ranking [ LV09 ], have been proposed to quantify structural distortions that occur between high-dimensional and low-dimensional data representations. Such measures could be evaluated and visualized point-wise to further highlight erroneous regions [ MLGH13 ]. In this work, we provide an interactive visualization framework for exploring high-dimensional data via its two-dimensional embeddings obtained from dimension reduction, using a rich set of user interactions. We ask the following question: what new insights do we obtain regarding the structure of the data, with interactive manipulations of its embeddings in the visual space? We augment the two-dimensional embeddings with structural abstrac- tions obtained from hierarchical clusterings, to help users navigate and manipulate subsets of the data. We use point-wise distortion measures to highlight interesting regions in the domain, and further to guide our selection of the appropriate level of clusterings that are aligned with the regions of interest. Under the static setting, point-wise distortions indicate the level of structural uncertainty within the embeddings. Under the dynamic setting, on-the-fly updates of point-wise distortions due to data movement and data deletion reflect structural relations among different parts of the data, which may lead to new and valuable insights.
Multivariate Volume Visualization through Dynamic Projections
Shusen Liu, Bei Wang, J.J. Thiagarajan, P.-T. Bremer, V. Pascucci.
“Multivariate Volume Visualization through Dynamic Projections,” In Proceedings of the IEEE Symposium on Large Data Analysis and Visualization (LDAV), 2014.
ABSTRACT
×
We propose a multivariate volume visualization framework that tightly couples dynamic projections with a high-dimensional transfer function design for interactive volume visualization. We assume that the complex, high-dimensional data in the attribute space can be well-represented through a collection of low-dimensional linear subspaces, and embed the data points in a variety of 2D views created as projections onto these subspaces. Through dynamic projections, we present animated transitions between different views to help the user navigate and explore the attribute space for effective transfer function design. Our framework not only provides a more intuitive understanding of the attribute space but also allows the design of the transfer function under multiple dynamic views, which is more flexible than being restricted to a single static view of the data. For large volumetric datasets, we maintain interactivity during the transfer function design via intelligent sampling and scalable clustering. Using examples in combustion and climate simulations, we demonstrate how our framework can be used to visualize interesting structures in the volumetric space.
Analyzing Simulation-Based {PRA} Data Through Clustering: a {BWR} Station Blackout Case Study
D. Maljovec, S. Liu, Bei Wang, V. Pascucci, P.-T. Bremer, D. Mandelli, C. Smith.
“Analyzing Simulation-Based PRA Data Through Clustering: a BWR Station Blackout Case Study,” In Proceedings of the Probabilistic Safety Assessment & Management conference (PSAM), 2014.
ABSTRACT
×
Dynamic probabilistic risk assessment (DPRA) methodologies couple system simulator codes (e.g., RELAP, MELCOR) with simulation controller codes (e.g., RAVEN, ADAPT). Whereas system simulator codes accurately model system dynamics deterministically, simulation controller codes introduce both deterministic (e.g., system control logic, operating procedures) and stochastic (e.g., component failures, parameter uncertainties) elements into the simulation. Typically, a DPRA is performed by 1) sampling values of a set of parameters from the uncertainty space of interest (using the simulation controller codes), and 2) simulating the system behavior for that specific set of parameter values (using the system simulator codes). For complex systems, one of the major challenges in using DPRA methodologies is to analyze the large amount of information (i.e., large number of scenarios ) generated, where clustering techniques are typically employed to allow users to better organize and interpret the data. In this paper, we focus on the analysis of a nuclear simulation dataset that is part of the risk-informed safety margin characterization (RISMC) boiling water reactor (BWR) station blackout (SBO) case study. We apply a software tool that provides the domain experts with an interactive analysis and visualization environment for understanding the structures of such high-dimensional nuclear simulation datasets. Our tool encodes traditional and topology-based clustering techniques, where the latter partitions the data points into clusters based on their uniform gradient flow behavior. We demonstrate through our case study that both types of clustering techniques complement each other in bringing enhanced structural understanding of the data.
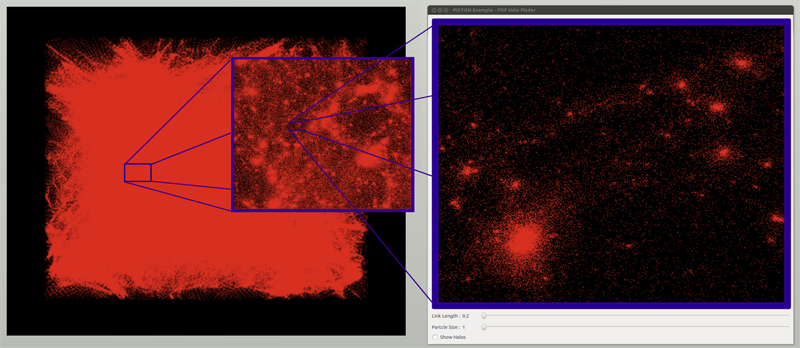
Data-Parallel Halo Finding with Variable Linking Lengths
W. Widanagamaachchi, P.-T. Bremer, C. Sewell, L.-T. Lo; J. Ahrens, V. Pascucci.
“Data-Parallel Halo Finding with Variable Linking Lengths,” In Proceedings of the 2014 IEEE 4th Symposium on Large Data Analysis and Visualization (LDAV), pp. 27--34. November, 2014.
ABSTRACT
×
State-of-the-art cosmological simulations regularly contain billions of particles, providing scientists the opportunity to study the evolution of the Universe in great detail. However, the rate at which these simulations generate data severely taxes existing analysis techniques. Therefore, developing new scalable alternatives is essential for continued scientific progress. Here, we present a dataparallel, friends-of-friends halo finding algorithm that provides unprecedented flexibility in the analysis by extracting multiple linking lengths. Even for a single linking length, it is as fast as the existing techniques, and is portable to multi-threaded many-core systems as well as co-processing resources. Our system is implemented using PISTON and is coupled to an interactive analysis environment used to study halos at different linking lengths and track their evolution over time.
2013
The Helmholtz-Hodge Decomposition - A Survey
H. Bhatia, G. Norgard, V. Pascucci, P.-T. Bremer.
“The Helmholtz-Hodge Decomposition - A Survey,” In IEEE Transactions on Visualization and Computer Graphics (TVCG), Vol. 19, No. 8, Note: Selected as Spotlight paper for August 2013 issue, pp. 1386--1404. 2013.
DOI: 10.1109/TVCG.2012.316
ABSTRACT
×
The Helmholtz-Hodge Decomposition (HHD) describes the decomposition of a flow field into its divergence-free and curl-free components. Many researchers in various communities like weather modeling, oceanology, geophysics, and computer graphics are interested in understanding the properties of flow representing physical phenomena such as incompressibility and vorticity. The HHD has proven to be an important tool in the analysis of fluids, making it one of the fundamental theorems in fluid dynamics. The recent advances in the area of flow analysis have led to the application of the HHD in a number of research communities such as flow visualization, topological analysis, imaging, and robotics. However, because the initial body of work, primarily in the physics communities, research on the topic has become fragmented with different communities working largely in isolation often repeating and sometimes contradicting each others results.