SCIENTIFIC COMPUTING AND IMAGING INSTITUTEat the University of Utah
An internationally recognized leader in visualization, scientific computing, and image analysis
SCI Publications
2014
Multivariate Volume Visualization through Dynamic Projections
Shusen Liu, Bei Wang, J.J. Thiagarajan, P.-T. Bremer, V. Pascucci.
“Multivariate Volume Visualization through Dynamic Projections,” In Proceedings of the IEEE Symposium on Large Data Analysis and Visualization (LDAV), 2014.
ABSTRACT
×
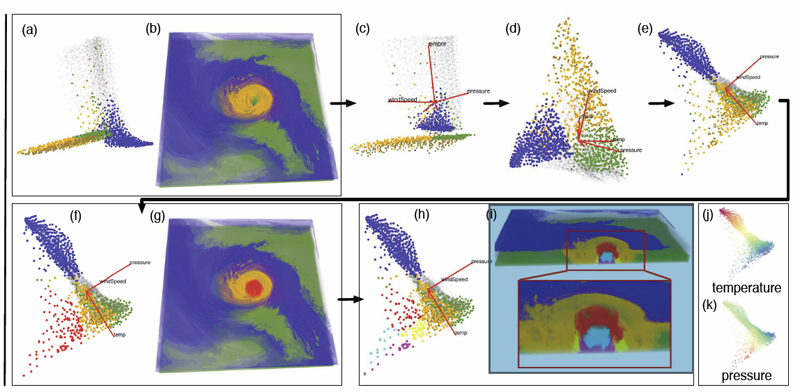
We propose a multivariate volume visualization framework that tightly couples dynamic projections with a high-dimensional transfer function design for interactive volume visualization. We assume that the complex, high-dimensional data in the attribute space can be well-represented through a collection of low-dimensional linear subspaces, and embed the data points in a variety of 2D views created as projections onto these subspaces. Through dynamic projections, we present animated transitions between different views to help the user navigate and explore the attribute space for effective transfer function design. Our framework not only provides a more intuitive understanding of the attribute space but also allows the design of the transfer function under multiple dynamic views, which is more flexible than being restricted to a single static view of the data. For large volumetric datasets, we maintain interactivity during the transfer function design via intelligent sampling and scalable clustering. Using examples in combustion and climate simulations, we demonstrate how our framework can be used to visualize interesting structures in the volumetric space.
Topology-Based Active Learning
D. Maljovec, Bei Wang, J. Moeller, V. Pascucci.
“Topology-Based Active Learning,” SCI Technical Report, No. UUSCI-2014-001, SCI Institute, University of Utah, 2014.
ABSTRACT
×
A common problem in simulation and experimental research involves obtaining time-consuming, expensive, or potentially hazardous samples from an arbitrary dimension parameter space. For example, many simulations modeled on supercomputers can take days or weeks to complete, so it is imperative to select samples in the most informative and interesting areas of the parameter space. In such environments, maximizing the potential gain of information is achieved through active learning (adaptive sampling). Though the topic of active learning is well-studied, this paper provides a new perspective on the problem. We consider topologybased batch selection strategies for active learning which are ideal for environments where parallel or concurrent experiments are able to be run, yet each has a heavy cost. These strategies utilize concepts derived from computational topology to choose a collection of locally distinct, optimal samples before updating the surrogate model. We demonstrate through experiments using a several different batch sizes that topology-based strategies have comparable and sometimes superior performance, compared to conventional approaches.
Analyzing Simulation-Based {PRA} Data Through Clustering: a {BWR} Station Blackout Case Study
D. Maljovec, S. Liu, Bei Wang, V. Pascucci, P.-T. Bremer, D. Mandelli, C. Smith.
“Analyzing Simulation-Based PRA Data Through Clustering: a BWR Station Blackout Case Study,” In Proceedings of the Probabilistic Safety Assessment & Management conference (PSAM), 2014.
ABSTRACT
×
Dynamic probabilistic risk assessment (DPRA) methodologies couple system simulator codes (e.g., RELAP, MELCOR) with simulation controller codes (e.g., RAVEN, ADAPT). Whereas system simulator codes accurately model system dynamics deterministically, simulation controller codes introduce both deterministic (e.g., system control logic, operating procedures) and stochastic (e.g., component failures, parameter uncertainties) elements into the simulation. Typically, a DPRA is performed by 1) sampling values of a set of parameters from the uncertainty space of interest (using the simulation controller codes), and 2) simulating the system behavior for that specific set of parameter values (using the system simulator codes). For complex systems, one of the major challenges in using DPRA methodologies is to analyze the large amount of information (i.e., large number of scenarios ) generated, where clustering techniques are typically employed to allow users to better organize and interpret the data. In this paper, we focus on the analysis of a nuclear simulation dataset that is part of the risk-informed safety margin characterization (RISMC) boiling water reactor (BWR) station blackout (SBO) case study. We apply a software tool that provides the domain experts with an interactive analysis and visualization environment for understanding the structures of such high-dimensional nuclear simulation datasets. Our tool encodes traditional and topology-based clustering techniques, where the latter partitions the data points into clusters based on their uniform gradient flow behavior. We demonstrate through our case study that both types of clustering techniques complement each other in bringing enhanced structural understanding of the data.
Overview of New Tools to Perform Safety Analysis: {BWR} Station Black Out Test Case
D. Mandelli, C. Smith, T. Riley, J. Nielsen, J. Schroeder, C. Rabiti, A. Alfonsi, J. Cogliati, R. Kinoshita, V. Pascucci, Bei Wang, D. Maljovec.
“Overview of New Tools to Perform Safety Analysis: BWR Station Black Out Test Case,” In Proceedings of the Probabilistic Safety Assessment & Management conference (PSAM), 2014.
ABSTRACT
×
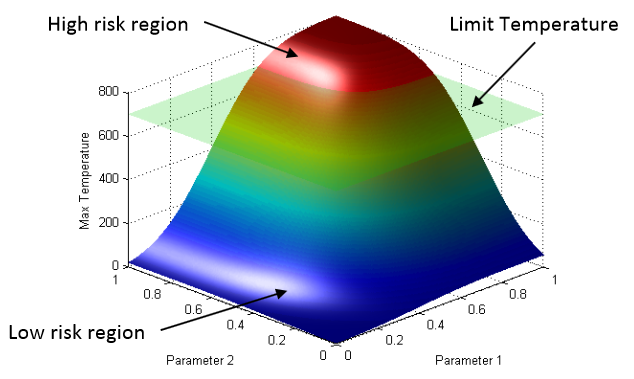
The existing fleet of nuclear power plants is in the process of extending its lifetime and increasing the power generated from these plants via power uprates. In order to evaluate the impacts of these two factors on the safety of the plant, the Risk Informed Safety Margin Characterization project aims to provide insights to decision makers through a series of simulations of the plant dynamics for different initial conditions (e.g., probabilistic analysis and uncertainty quantification). This paper focuses on the impacts of power uprate on the safety margin of a boiling water reactor for a station black-out event. Analysis is performed by using a combination of thermal-hydraulic codes and a stochastic analysis tool currently under development at the Idaho National Laboratory, i.e. RAVEN. We employed both classical statistical tools, i.e. Monte-Carlo, and more advanced machine learning based algorithms to perform uncertainty quantification in order to quantify changes in system performance and limitations as a consequence of power uprate. We also employed advanced data analysis and visualization tools that helped us to correlate simulation outcomes such as maximum core temperature with a set of input uncertain parameters. Results obtained give a detailed investigation of the issues associated with a plant power uprate including the effects of station black-out accident scenarios. We were able to quantify how the timing of specific events was impacted by a higher nominal reactor core power. Such safety insights can provide useful information to the decision makers to perform risk-informed margins management.
Towards Paint and Click: Unified Interactions for Image Boundaries
B. Summa, A.A. Gooch, G. Scorzelli, V. Pascucci.
“Towards Paint and Click: Unified Interactions for Image Boundaries,” SCI Technical Report, No. UUSCI-2014-004, SCI Institute, University of Utah, December, 2014.
ABSTRACT
×
Image boundaries are a fundamental component of many interactive digital photography techniques, enabling applications such as segmentation, panoramas, and seamless image composition. Interactions for image boundaries often rely on two complimentary but separate approaches: editing via painting or clicking constraints. In this work, we provide a novel, unified approach for interactive editing of pairwise image boundaries that combines the ease of painting with the direct control of constraints. Rather than a sequential coupling, this new formulation allows full use of both interactions simultaneously, giving users unprecedented flexibility for fast boundary editing. To enable this new approach, we provide technical advancements. In particular, we detail a reformulation of image boundaries as a problem of finding cycles, expanding and correcting limitations of the previous work. Our new formulation provides boundary solutions for painted regions with performance on par with state-of-the-art specialized, paint-only techniques. In addition, we provide instantaneous exploration of the boundary solution space with user constraints. Furthermore, we show how to increase performance and decrease memory consumption through novel strategies and/or optional approximations. Finally, we provide examples of common graphics applications impacted by our new approach.
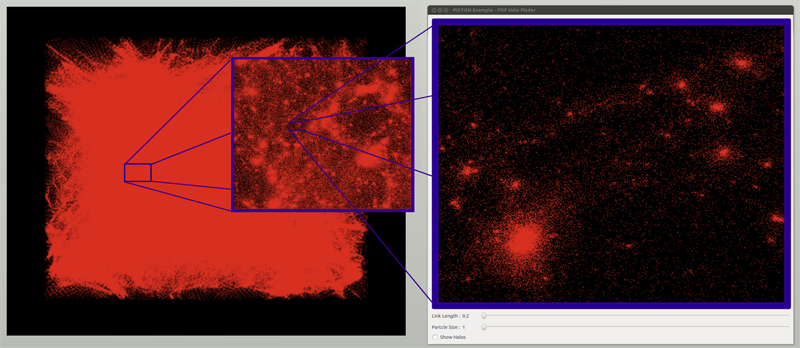
Data-Parallel Halo Finding with Variable Linking Lengths
W. Widanagamaachchi, P.-T. Bremer, C. Sewell, L.-T. Lo; J. Ahrens, V. Pascucci.
“Data-Parallel Halo Finding with Variable Linking Lengths,” In Proceedings of the 2014 IEEE 4th Symposium on Large Data Analysis and Visualization (LDAV), pp. 27--34. November, 2014.
ABSTRACT
×
State-of-the-art cosmological simulations regularly contain billions of particles, providing scientists the opportunity to study the evolution of the Universe in great detail. However, the rate at which these simulations generate data severely taxes existing analysis techniques. Therefore, developing new scalable alternatives is essential for continued scientific progress. Here, we present a dataparallel, friends-of-friends halo finding algorithm that provides unprecedented flexibility in the analysis by extracting multiple linking lengths. Even for a single linking length, it is as fast as the existing techniques, and is portable to multi-threaded many-core systems as well as co-processing resources. Our system is implemented using PISTON and is coupled to an interactive analysis environment used to study halos at different linking lengths and track their evolution over time.
2013
The Helmholtz-Hodge Decomposition - A Survey
H. Bhatia, G. Norgard, V. Pascucci, P.-T. Bremer.
“The Helmholtz-Hodge Decomposition - A Survey,” In IEEE Transactions on Visualization and Computer Graphics (TVCG), Vol. 19, No. 8, Note: Selected as Spotlight paper for August 2013 issue, pp. 1386--1404. 2013.
DOI: 10.1109/TVCG.2012.316
ABSTRACT
×
The Helmholtz-Hodge Decomposition (HHD) describes the decomposition of a flow field into its divergence-free and curl-free components. Many researchers in various communities like weather modeling, oceanology, geophysics, and computer graphics are interested in understanding the properties of flow representing physical phenomena such as incompressibility and vorticity. The HHD has proven to be an important tool in the analysis of fluids, making it one of the fundamental theorems in fluid dynamics. The recent advances in the area of flow analysis have led to the application of the HHD in a number of research communities such as flow visualization, topological analysis, imaging, and robotics. However, because the initial body of work, primarily in the physics communities, research on the topic has become fragmented with different communities working largely in isolation often repeating and sometimes contradicting each others results.
Comments on the “Meshless Helmholtz-Hodge decomposition”
H. Bhatia, G. Norgard, V. Pascucci, P.-T. Bremer.
“Comments on the “Meshless Helmholtz-Hodge decomposition”,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 19, No. 3, pp. 527--528. 2013.
DOI: 10.1109/TVCG.2012.62
ABSTRACT
The Helmholtz-Hodge decomposition (HHD) is one of the fundamental theorems of fluids describing the decomposition of a flow field into its divergence-free, curl-free and harmonic components. Solving for an HDD is intimately connected to the choice of boundary conditions which determine the uniqueness and orthogonality of the decomposition. This article points out that one of the boundary conditions used in a recent paper \"Meshless Helmholtz-Hodge decomposition\" [5] is, in general, invalid and provides an analytical example demonstrating the problem. We hope that this clarification on the theory will foster further research in this area and prevent undue problems in applying and extending the original approach.
Topology analysis of time-dependent multi-fluid data using the Reeb graph
F. Chen, H. Obermaier, H. Hagen, B. Hamann, J. Tierny, V. Pascucci.
“Topology analysis of time-dependent multi-fluid data using the Reeb graph,” In Computer Aided Geometric Design, Vol. 30, No. 6, pp. 557--566. 2013.
DOI: 10.1016/j.cagd.2012.03.019
ABSTRACT
×
Liquid–liquid extraction is a typical multi-fluid problem in chemical engineering where two types of immiscible fluids are mixed together. Mixing of two-phase fluids results in a time-varying fluid density distribution, quantitatively indicating the presence of liquid phases. For engineers who design extraction devices, it is crucial to understand the density distribution of each fluid, particularly flow regions that have a high concentration of the dispersed phase. The propagation of regions of high density can be studied by examining the topology of isosurfaces of the density data. We present a topology-based approach to track the splitting and merging events of these regions using the Reeb graphs. Time is used as the third dimension in addition to two-dimensional (2D) point-based simulation data. Due to low time resolution of the input data set, a physics-based interpolation scheme is required in order to improve the accuracy of the proposed topology tracking method. The model used for interpolation produces a smooth time-dependent density field by applying Lagrangian-based advection to the given simulated point cloud data, conforming to the physical laws of flow evolution. Using the Reeb graph, the spatial and temporal locations of bifurcation and merging events can be readily identified supporting in-depth analysis of the extraction process.
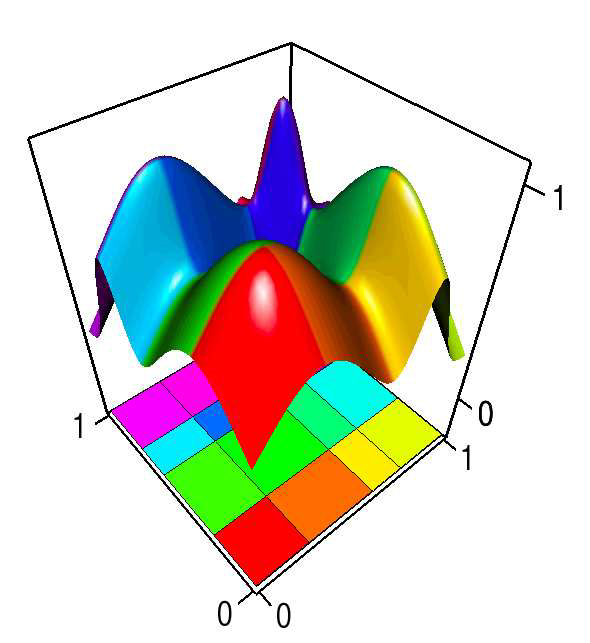
S. Gerber, O. Reubel, P.-T. Bremer, V. Pascucci, R.T. Whitaker.
“Morse-Smale Regression,” In Journal of Computational and Graphical Statistics, Vol. 22, No. 1, pp. 193--214. 2013.
DOI: 10.1080/10618600.2012.657132
ABSTRACT
×
This paper introduces a novel partition-based regression approach that incorporates topological information. Partition-based regression typically introduce a quality-of-fit-driven decomposition of the domain. The emphasis in this work is on a topologically meaningful segmentation. Thus, the proposed regression approach is based on a segmentation induced by a discrete approximation of the Morse-Smale complex. This yields a segmentation with partitions corresponding to regions of the function with a single minimum and maximum that are often well approximated by a linear model. This approach yields regression models that are amenable to interpretation and have good predictive capacity. Typically, regression estimates are quantified by their geometrical accuracy. For the proposed regression, an important aspect is the quality of the segmentation itself. Thus, this paper introduces a new criterion that measures the topological accuracy of the estimate. The topological accuracy provides a complementary measure to the classical geometrical error measures and is very sensitive to over-fitting. The Morse-Smale regression is compared to state-of-the-art approaches in terms of geometry and topology and yields comparable or improved fits in many cases. Finally, a detailed study on climate-simulation data demonstrates the application of the Morse-Smale regression. Supplementary materials are available online and contain an implementation of the proposed approach in the R package msr, an analysis and simulations on the stability of the Morse-Smale complex approximation and additional tables for the climate-simulation study.
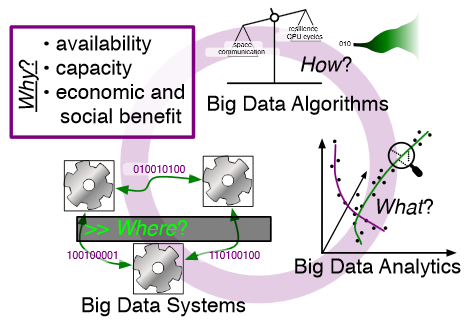
Rethinking Abstractions for Big Data: Why, Where, How, and What
M. Hall, R.M. Kirby, F. Li, M.D. Meyer, V. Pascucci, J.M. Phillips, R. Ricci, J. Van der Merwe, S. Venkatasubramanian.
“Rethinking Abstractions for Big Data: Why, Where, How, and What,” In Cornell University Library, 2013.
ABSTRACT
×
Big data refers to large and complex data sets that, under existing approaches, exceed the capacity and capability of current compute platforms, systems software, analytical tools and human understanding [7]. Numerous lessons on the scalability of big data can already be found in asymptotic analysis of algorithms and from the high-performance computing (HPC) and applications communities. However, scale is only one aspect of current big data trends; fundamentally, current and emerging problems in big data are a result of unprecedented complexity |in the structure of the data and how to analyze it, in dealing with unreliability and redundancy, in addressing the human factors of comprehending complex data sets, in formulating meaningful analyses, and in managing the dense, power-hungry data centers that house big data.
The computer science solution to complexity is finding the right abstractions, those that hide as much triviality as possible while revealing the essence of the problem that is being addressed. The "big data challenge" has disrupted computer science by stressing to the very limits the familiar abstractions which define the relevant subfields in data analysis, data management and the underlying parallel systems. Efficient processing of big data has shifted systems towards increasingly heterogeneous and specialized units, with resilience and energy becoming important considerations. The design and analysis of algorithms must now incorporate emerging costs in communicating data driven by IO costs, distributed data, and the growing energy cost of these operations. Data analysis representations as structural patterns and visualizations surpass human visual bandwidth, structures studied at small scale are rare at large scale, and large-scale high-dimensional phenomena cannot be reproduced at small scale.
As a result, not enough of these challenges are revealed by isolating abstractions in a traditional soft-ware stack or standard algorithmic and analytical techniques, and attempts to address complexity either oversimplify or require low-level management of details. The authors believe that the abstractions for big data need to be rethought, and this reorganization needs to evolve and be sustained through continued cross-disciplinary collaboration.
In what follows, we first consider the question of why big data and why now. We then describe the where (big data systems), the how (big data algorithms), and the what (big data analytics) challenges that we believe are central and must be addressed as the research community develops these new abstractions. We equate the biggest challenges that span these areas of big data with big mythological creatures, namely cyclops, that should be conquered.
Characterization and modeling of {PIDX} parallel {I/O} for performance optimization
S. Kumar, A. Saha, V. Vishwanath, P. Carns, J.A. Schmidt, G. Scorzelli, H. Kolla, R. Grout, R. Latham, R. Ross, M.E. Papka, J. Chen, V. Pascucci.
“Characterization and modeling of PIDX parallel I/O for performance optimization,” In Proceedings of SC13: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 67. 2013.
ABSTRACT
Parallel I/O library performance can vary greatly in response to user-tunable parameter values such as aggregator count, file count, and aggregation strategy. Unfortunately, manual selection of these values is time consuming and dependent on characteristics of the target machine, the underlying file system, and the dataset itself. Some characteristics, such as the amount of memory per core, can also impose hard constraints on the range of viable parameter values. In this work we address these problems by using machine learning techniques to model the performance of the PIDX parallel I/O library and select appropriate tunable parameter values. We characterize both the network and I/O phases of PIDX on a Cray XE6 as well as an IBM Blue Gene/P system. We use the results of this study to develop a machine learning model for parameter space exploration and performance prediction.
Exploration of High-Dimensional Scalar Function for Nuclear Reactor Safety Analysis and Visualization
D. Maljovec, Bei Wang, V. Pascucci, P.-T. Bremer, M.Pernice, D. Mandelli, R. Nourgaliev.
“Exploration of High-Dimensional Scalar Function for Nuclear Reactor Safety Analysis and Visualization,” In Proceedings of the 2013 International Conference on Mathematics and Computational Methods Applied to Nuclear Science & Engineering (M&C), pp. 712-723. 2013.
ABSTRACT
×
The next generation of methodologies for nuclear reactor Probabilistic Risk Assessment (PRA) explicitly accounts for the time element in modeling the probabilistic system evolution and uses numerical simulation tools to account for possible dependencies between failure events. The Monte-Carlo (MC) and the Dynamic Event Tree (DET) approaches belong to this new class of dynamic PRA methodologies. A challenge of dynamic PRA algorithms is the large amount of data they produce which may be difficult to visualize and analyze in order to extract useful information. We present a software tool that is designed to address these goals. We model a large-scale nuclear simulation dataset as a high-dimensional scalar function defined over a discrete sample of the domain. First, we provide structural analysis of such a function at multiple scales and provide insight into the relationship between the input parameters and the output. Second, we enable exploratory analysis for users, where we help the users to differentiate features from noise through multi-scale analysis on an interactive platform, based on domain knowledge and data characterization. Our analysis is performed by exploiting the topological and geometric properties of the domain, building statistical models based on its topological segmentations and providing interactive visual interfaces to facilitate such explorations. We provide a user's guide to our software tool by highlighting its analysis and visualization capabilities, along with a use case involving data from a nuclear reactor safety simulation.
Adaptive Sampling Algorithms for Probabilistic Risk Assessment of Nuclear Simulations
D. Maljovec, Bei Wang, D. Mandelli, P.-T. Bremer, V. Pascucci.
“Adaptive Sampling Algorithms for Probabilistic Risk Assessment of Nuclear Simulations,” In Proceedings of the 2013 International Topical Meeting on Probabilistic Safety Assessment and Analysis (PSA 2013), Note: First runner-up for Best Student Paper Award, 2013.
ABSTRACT
×
Nuclear simulations are often computationally expensive, time-consuming, and high-dimensional with respect to the number of input parameters. Thus exploring the space of all possible simulation outcomes is infeasible using finite computing resources. During simulation-based probabilistic risk analysis, it is important to discover the relationship between a potentially large number of input parameters and the output of a simulation using as few simulation trials as possible. This is a typical context for performing adaptive sampling where a few observations are obtained from the simulation, a surrogate model is built to represent the simulation space, and new samples are selected based on the model constructed. The surrogate model is then updated based on the simulation results of the sampled points. In this way, we attempt to gain the most information possible with a small number of carefully selected sampled points, limiting the number of expensive trials needed to understand features of the simulation space.
We analyze the specific use case of identifying the limit surface, i.e., the boundaries in the simulation space between system failure and system success. In this study, we explore several techniques for adaptively sampling the parameter space in order to reconstruct the limit surface. We focus on several adaptive sampling schemes. First, we seek to learn a global model of the entire simulation space using prediction models or neighborhood graphs and extract the limit surface as an iso-surface of the global model. Second, we estimate the limit surface by sampling in the neighborhood of the current estimate based on topological segmentations obtained locally.
Our techniques draw inspirations from topological structure known as the Morse-Smale complex. We highlight the advantages and disadvantages of using a global prediction model versus local topological view of the simulation space, comparing several different strategies for adaptive sampling in both contexts. One of the most interesting models we propose attempt to marry the two by obtaining a coarse global representation using prediction models, and a detailed local representation based on topology. Our methods are validated on several analytical test functions as well as a small nuclear simulation dataset modeled after a simplified Pressurized Water Reactor.
Analyze Dynamic Probabilistic Risk Assessment Data through Clustering
D. Maljovec, Bei Wang, D. Mandelli, P.-T. Bremer, V. Pascucci.
“Analyze Dynamic Probabilistic Risk Assessment Data through Clustering,” In Proceedings of the 2013 International Topical Meeting on Probabilistic Safety Assessment and Analysis (PSA 2013), 2013.
ABSTRACT
×
We investigate the use of a topology-based clustering technique on the data generated by dynamic event tree methodologies. The clustering technique we utilizes focuses on a domain-partitioning algorithm based on topological structures known as the Morse-Smale complex, which partitions the data points into clusters based on their uniform gradient flow behavior. We perform both end state analysis and transient analysis to classify the set of nuclear scenarios. We demonstrate our methodology on a dataset generated for a sodium-cooled fast reactor during an aircraft crash scenario. The simulation tracks the temperature of the reactor as well as the time for a recovery team to fix the passive cooling system. Combined with clustering results obtained previously through mean shift methodology, we present the user with complementary views of the data that help illuminate key features that may be otherwise hidden using a single methodology. By clustering the data, the number of relevant test cases to be selected for further analysis can be drastically reduced by selecting a representative from each cluster. Identifying the similarities of simulations within a cluster can also aid in the drawing of important conclusions with respect to safety analysis.
Adaptive Sampling with Topological Scores
D. Maljovec, Bei Wang, A. Kupresanin, G. Johannesson, V. Pascucci, P.-T. Bremer.
“Adaptive Sampling with Topological Scores,” In Int. J. Uncertainty Quantification, Vol. 3, No. 2, Begell House, pp. 119--141. 2013.
DOI: 10.1615/int.j.uncertaintyquantification.2012003955
ABSTRACT
Understanding and describing expensive black box functions such as physical simulations is a common problem in many application areas. One example is the recent interest in uncertainty quantification with the goal of discovering the relationship between a potentially large number of input parameters and the output of a simulation. Typically, the simulation of interest is expensive to evaluate and thus the sampling of the parameter space is necessarily small. As a result choosing a "good" set of samples at which to evaluate is crucial to glean as much information as possible from the fewest samples. While space-filling sampling designs such as Latin hypercubes provide a good initial cover of the entire domain, more detailed studies typically rely on adaptive sampling: Given an initial set of samples, these techniques construct a surrogate model and use it to evaluate a scoring function which aims to predict the expected gain from evaluating a potential new sample. There exist a large number of different surrogate models as well as different scoring functions each with their own advantages and disadvantages. In this paper we present an extensive comparative study of adaptive sampling using four popular regression models combined with six traditional scoring functions compared against a space-filling design. Furthermore, for a single high-dimensional output function, we introduce a new class of scoring functions based on global topological rather than local geometric information. The new scoring functions are competitive in terms of the root mean squared prediction error but are expected to better recover the global topological structure. Our experiments suggest that the most common point of failure of adaptive sampling schemes are ill-suited regression models. Nevertheless, even given well-fitted surrogate models many scoring functions fail to outperform a space-filling design.
Scalable Visualization and Interactive Analysis Using Massive Data Streams
V. Pascucci, P.-T. Bremer, A. Gyulassy, G. Scorzelli, C. Christensen, B. Summa, S. Kumar.
“Scalable Visualization and Interactive Analysis Using Massive Data Streams,” In Cloud Computing and Big Data, Advances in Parallel Computing, Vol. 23, IOS Press, pp. 212--230. 2013.
ABSTRACT
×
Historically, data creation and storage has always outpaced the infrastructure for its movement and utilization. This trend is increasing now more than ever, with the ever growing size of scientific simulations, increased resolution of sensors, and large mosaic images. Effective exploration of massive scientific models demands the combination of data management, analysis, and visualization techniques, working together in an interactive setting. The ViSUS application framework has been designed as an environment that allows the interactive exploration and analysis of massive scientific models in a cache-oblivious, hardware-agnostic manner, enabling processing and visualization of possibly geographically distributed data using many kinds of devices and platforms.
For general purpose feature segmentation and exploration we discuss a new paradigm based on topological analysis. This approach enables the extraction of summaries of features present in the data through abstract models that are orders of magnitude smaller than the raw data, providing enough information to support general queries and perform a wide range of analyses without access to the original data.
Keywords: Visualization, data analysis, topological data analysis, Parallel I/O
Scalable Seams for Gigapixel Panoramas
S. Philip, B. Summa, J. Tierny, P.-T. Bremer, V. Pascucci.
“Scalable Seams for Gigapixel Panoramas,” In Proceedings of the 2013 Eurographics Symposium on Parallel Graphics and Visualization, Note: Awarded Best Paper!, pp. 25--32. 2013.
DOI: 10.2312/EGPGV/EGPGV13/025-032
ABSTRACT
×
Gigapixel panoramas are an increasingly popular digital image application. They are often created as a mosaic of smaller images composited into a larger single image. The mosaic acquisition can occur over many hours causing the individual images to differ in exposure and lighting conditions. Therefore, to give the appearance of a single seamless image a blending operation is necessary. The quality of this blending depends on the magnitude of discontinuity along the boundaries between the images. Often image boundaries, or seams, are first computed to minimize this transition. Current techniques based on the multi-labeling Graph Cuts method are too slow and memory intensive for panoramas many gigapixels in size. In this paper we present a multithreaded out-of-core seam computing technique that is fast, has a small memory footprint, and gives near perfect scaling up to the number of physical cores of our test system. With this method the time required to compute image boundaries for gigapixel imagery improves from many hours (or even days) to just a few minutes on commodity hardware while still producing boundaries with energy that is on-par, if not better, than Graph Cuts.
{ManyVis}: Multiple Applications in an Integrated Visualization Environment
A. Rungta, B. Summa, D. Demir, P.-T. Bremer, V. Pascucci.
“ManyVis: Multiple Applications in an Integrated Visualization Environment,” In IEEE Transactions on Visualization and Computer Graphics (TVCG), Vol. 19, No. 12, pp. 2878--2885. December, 2013.
ABSTRACT
×
As the visualization field matures, an increasing number of general toolkits are developed to cover a broad range of applications. However, no general tool can incorporate the latest capabilities for all possible applications, nor can the user interfaces and workflows be easily adjusted to accommodate all user communities. As a result, users will often chose either substandard solutions presented in familiar, customized tools or assemble a patchwork of individual applications glued through ad-hoc scripts and extensive, manual intervention. Instead, we need the ability to easily and rapidly assemble the best-in-task tools into custom interfaces and workflows to optimally serve any given application community. Unfortunately, creating such meta-applications at the API or SDK level is difficult, time consuming, and often infeasible due to the sheer variety of data models, design philosophies, limits in functionality, and the use of closed commercial systems. In this paper, we present the ManyVis framework which enables custom solutions to be built both rapidly and simply by allowing coordination and communication across existing unrelated applications. ManyVis allows users to combine software tools with complementary characteristics into one virtual application driven by a single, custom-designed interface.
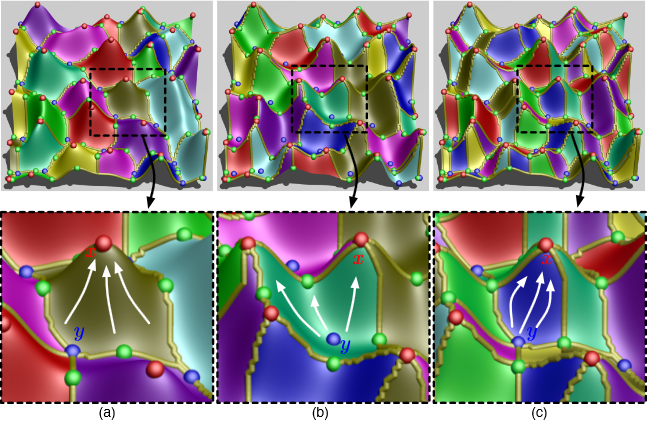
Visualizing Robustness of Critical Points for {2D} Time-Varying Vector Fields
Analyzing critical points and their temporal evolutions plays a crucial role in understanding the behavior of vector fields. A key challenge is to quantify the stability of critical points: more stable points may represent more important phenomena or vice versa. The topological notion of robustness is a tool which allows us to quantify rigorously the stability of each critical point. Intuitively, the robustness of a critical point is the minimum amount of perturbation necessary to cancel it within a local neighborhood, measured under an appropriate metric. In this paper, we introduce a new analysis and visualization framework which enables interactive exploration of robustness of critical points for both stationary and time-varying 2D vector fields. This framework allows the end-users, for the first time, to investigate how the stability of a critical point evolves over time. We show that this depends heavily on the global properties of the vector field and that structural changes can correspond to interesting behavior. We demonstrate the practicality of our theories and techniques on several datasets involving combustion and oceanic eddy simulations and obtain some key insights regarding their stable and unstable features.