




SCI Publications
2011


Attila Gyulassy, J.A. Levine, V. Pascucci.
“Visualization of Discrete Gradient Construction (Multimedia submission),” In Proceedings of the 27th Symposium on Computational Geometry, Paris, France, ACM, pp. 289--290. June, 2011.
DOI: 10.1145/1998196.1998241

S. Jadhav, H. Bhatia, P.-T. Bremer, J.A. Levine, L.G. Nonato, V. Pascucci.
“Consistent Approximation of Local Flow Behavior for 2D Vector Fields,” In Mathematics and Visualization, Springer, pp. 141--159. Nov, 2011.
DOI: 10.1007/978-3-642-23175-9 10
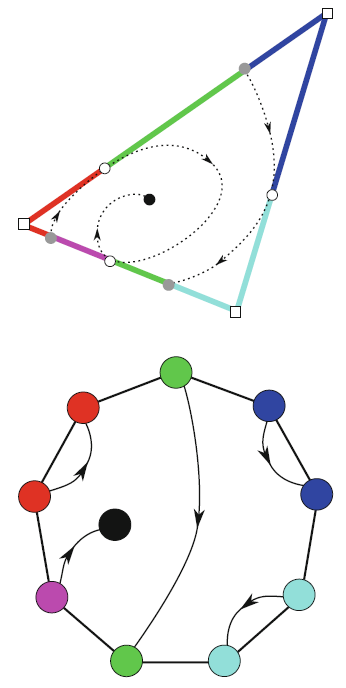
Typically, vector fields are stored as a set of sample vectors at discrete locations. Vector values at unsampled points are defined by interpolating some subset of the known sample values. In this work, we consider two-dimensional domains represented as triangular meshes with samples at all vertices, and vector values on the interior of each triangle are computed by piecewise linear interpolation.
Many of the commonly used techniques for studying properties of the vector field require integration techniques that are prone to inconsistent results. Analysis based on such inconsistent results may lead to incorrect conclusions about the data. For example, vector field visualization techniques integrate the paths of massless particles (streamlines) in the flow or advect a texture using line integral convolution (LIC). Techniques like computation of the topological skeleton of a vector field, require integrating separatrices, which are streamlines that asymptotically bound regions where the flow behaves differently. Since these integrations may lead to compound numerical errors, the computed streamlines may intersect, violating some of their fundamental properties such as being pairwise disjoint. Detecting these computational artifacts to allow further analysis to proceed normally remains a significant challenge.
S. Kumar, V. Vishwanath, P. Carns, B. Summa, G. Scorzelli, V. Pascucci, R. Ross, J. Chen, H. Kolla, R. Grout.
“PIDX: Efficient Parallel I/O for Multi-resolution Multi-dimensional Scientific Datasets,” In Proceedings of The IEEE International Conference on Cluster Computing, pp. 103--111. September, 2011.
T. Peterka, R. Ross, A. Gyulassy, V. Pascucci, W. Kendall, H.-W. Shen, T.-Y. Lee, A. Chaudhuri.
“Scalable Parallel Building Blocks for Custom Data Analysis,” In Proceedings of the 2011 IEEE Symposium on Large-Scale Data Analysis and Visualization (LDAV), pp. 105--112. October, 2011.
DOI: 10.1109/LDAV.2011.6092324
We present a set of building blocks that provide scalable data movement capability to computational scientists and visualization researchers for writing their own parallel analysis. The set includes scalable tools for domain decomposition, process assignment, parallel I/O, global reduction, and local neighborhood communicationtasks that are common across many analysis applications. The global reduction is performed with a new algorithm, described in this paper, that efficiently merges blocks of analysis results into a smaller number of larger blocks. The merging is configurable in the number of blocks that are reduced in each round, the number of rounds, and the total number of resulting blocks. We highlight the use of our library in two analysis applications: parallel streamline generation and parallel Morse-Smale topological analysis. The first case uses an existing local neighborhood communication algorithm, whereas the latter uses the new merge algorithm.
S. Philip, B. Summa, P.-T. Bremer, and V. Pascucci.
“Parallel Gradient Domain Processing of Massive Images,” In Proceedings of the 2011 Eurographics Symposium on Parallel Graphics and Visualization, pp. 11--19. 2011.

S. Philip, B. Summa, P-T Bremer, V. Pascucci.
“Hybrid CPU-GPU Solver for Gradient Domain Processing of Massive Images,” In Proceedings of 2011 International Conference on Parallel and Distributed Systems (ICPADS), pp. 244--251. 2011.

M. Schulz, J.A. Levine, P.-T. Bremer, T. Gamblin, V. Pascucci.
“Interpreting Performance Data Across Intuitive Domains,” In International Conference on Parallel Processing, Taipei, Taiwan, IEEE, pp. 206--215. 2011.
DOI: 10.1109/ICPP.2011.60
B. Summa, G. Scorzelli, M. Jiang, P.-T. Bremer, V. Pascucci.
“Interactive Editing of Massive Imagery Made Simple: Turning Atlanta into Atlantis,” In ACM Transactions on Graphics, Vol. 30, No. 2, pp. 7:1--7:13. April, 2011.
DOI: 10.1145/1944846.1944847
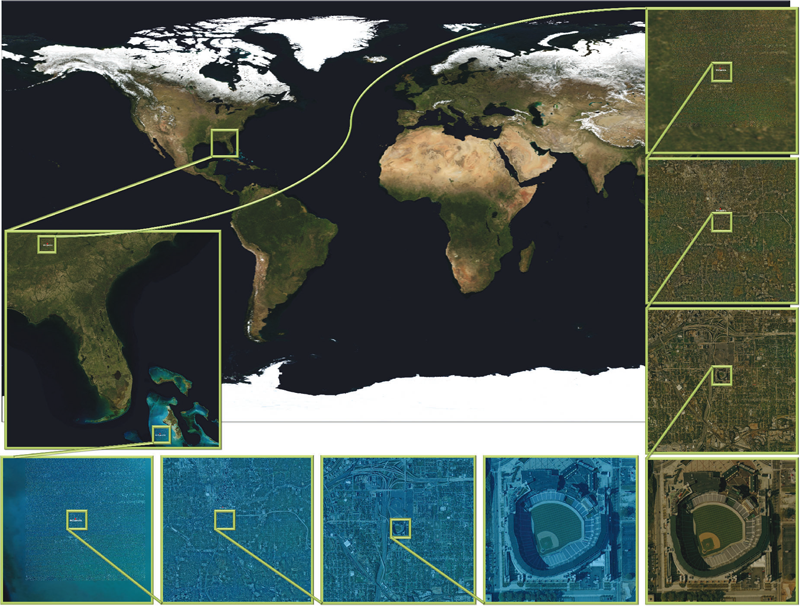
This article presents a simple framework for progressive processing of high-resolution images with minimal resources. We demonstrate this framework's effectiveness by implementing an adaptive, multi-resolution solver for gradient-based image processing that, for the first time, is capable of handling gigapixel imagery in real time. With our system, artists can use commodity hardware to interactively edit massive imagery and apply complex operators, such as seamless cloning, panorama stitching, and tone mapping.
We introduce a progressive Poisson solver that processes images in a purely coarse-to-fine manner, providing near instantaneous global approximations for interactive display (see Figure 1). We also allow for data-driven adaptive refinements to locally emulate the effects of a global solution. These techniques, combined with a fast, cache-friendly data access mechanism, allow the user to interactively explore and edit massive imagery, with the illusion of having a full solution at hand. In particular, we demonstrate the interactive modification of gigapixel panoramas that previously required extensive offline processing. Even with massive satellite images surpassing a hundred gigapixels in size, we enable repeated interactive editing in a dynamically changing environment. Images at these scales are significantly beyond the purview of previous methods yet are processed interactively using our techniques. Finally our system provides a robust and scalable out-of-core solver that consistently offers high-quality solutions while maintaining strict control over system resources.
D. Thompson, J.A. Levine, J.C. Bennett, P.-T. Bremer, A. Gyulassy, V. Pascucci, P.P. Pebay.
“Analysis of Large-Scale Scalar Data Using Hixels,” In Proceedings of the 2011 IEEE Symposium on Large-Scale Data Analysis and Visualization (LDAV), Providence, RI, pp. 23--30. 2011.
DOI: 10.1109/LDAV.2011.6092313
H.T. Vo, J. Bronson, B. Summa, J.L.D. Comba, J. Freire, B. Howe, V. Pascucci, C.T. Silva.
“Parallel Visualization on Large Clusters using MapReduce,” SCI Technical Report, No. UUSCI-2011-002, SCI Institute, University of Utah, 2011.
H.T. Vo, J. Bronson, B. Summa, J.L.D. Comba, J. Freire, B. Howe, V. Pascucci, C.T. Silva.
“Parallel Visualization on Large Clusters using MapReduce,” In Proceedings of the 2011 IEEE Symposium on Large-Scale Data Analysis and Visualization (LDAV), pp. 81--88. 2011.
Keywords: MapReduce, Hadoop, cloud computing, large meshes, volume rendering, gigapixels
H.T. Vo, C.T. Silva, L.F. Scheidegger, V. Pascucci.
“Simple and Efficient Mesh Layout with Space-Filling Curves,” In Journal of Graphics, GPU, and Game Tools, pp. 25--39. 2011.
ISSN: 2151-237X
Bei Wang, B. Summa, V. Pascucci, M. Vejdemo-Johansson.
“Branching and Circular Features in High Dimensional Data,” SCI Technical Report, No. UUSCI-2011-005, SCI Institute, University of Utah, 2011.
Bei Wang, B. Summa, V. Pascucci, M. Vejdemo-Johansson.
“Branching and Circular Features in High Dimensional Data,” In IEEE Transactions of Visualization and Computer Graphics (TVCG), Vol. 17, No. 12, pp. 1902--1911. 2011.
DOI: 10.1109/TVCG.2011.177
PubMed ID: 22034307
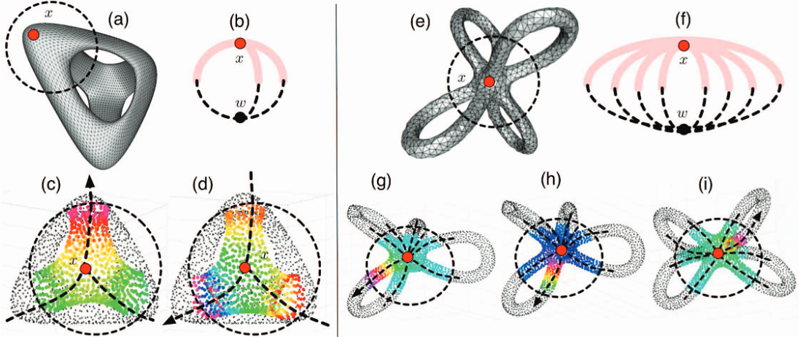
Keywords: Dimensionality reduction, circular coordinates, visualization, topological analysis
S. Williams, M. Petersen, P.-T. Bremer, M. Hecht, V. Pascucci, J. Ahrens, M. Hlawitschka, B. Hamann.
“Adaptive Extraction and Quantification of Geophysical Vortices,” In IEEE Transactions on Visualization and Computer Graphics, Proceedings of the 2011 IEEE Visualization Conference, Vol. 17, No. 12, pp. 2088--2095. 2011.
2010
M. Berger, L.G. Nonato, V. Pascucci, C.T. Silva.
“Fiedler Trees for Multiscale Surface Analysis,” In Computer & Graphics, Vol. 34, No. 3, Note: Special Issue of Sha, pp. 272--281. June, 2010.
DOI: 10.1016/j.cag.2010.03.009
In this work we introduce a new hierarchical surface decomposition method for multiscale analysis of surface meshes. In contrast to other multiresolution methods, our approach relies on spectral properties of the surface to build a binary hierarchical decomposition. Namely, we utilize the first nontrivial eigenfunction of the Laplace–Beltrami operator to recursively decompose the surface. For this reason we coin our surface decomposition the Fiedler tree. Using the Fiedler tree ensures a number of attractive properties, including: mesh-independent decomposition, well-formed and nearly equi-areal surface patches, and noise robustness. We show how the evenly distributed patches can be exploited for generating multiresolution high quality uniform meshes. Additionally, our decomposition permits a natural means for carrying out wavelet methods, resulting in an intuitive method for producing feature-sensitive meshes at multiple scales.
T. Etiene, L.G. Nonato, C.E. Scheidegger, J. Tierny, T.J. Peters, V. Pascucci, R.M. Kirby, C.T. Silva.
“Topology Verification for Isosurface Extraction,” SCI Technical Report, No. UUSCI-2010-003, SCI Institute, University of Utah, 2010.
S. Gerber, P.-T. Bremer, V. Pascucci, R.T. Whitaker.
“Visual Exploration of High Dimensional Scalar Functions,” In IEEE Transactions on Visualization and Computer Graphics, IEEE Transactions on Visualization and Computer Graphics, Vol. 16, No. 6, IEEE, pp. 1271--1280. Nov, 2010.
DOI: 10.1109/TVCG.2010.213
PubMed ID: 20975167
PubMed Central ID: PMC3099238
S. Jadhav, H. Bhatia, P.-T. Bremer, J.A. Levine, L.G. Nonato, V. Pascucci.
“Consistent Approximation of Local Flow Behavior for 2D Vector Fields using Edge Maps,” SCI Technical Report, No. UUSCI-2010-004, SCI Institute, University of Utah, 2010.
S. Kumar, V. Vishwanath, P. Carns, V. Pascucci, R. Latham, T. Peterka, M. Papka, R. Ross.
“Towards Efficient Access of Multi-dimensional, Multi-resolution Scientific Data,” In Proceedings of the 5th Petascale Data Storage Workshop, Supercomputing 2010, pp. (in press). 2010.