




Scientific Computing
Numerical simulation of real-world phenomena provides fertile ground for building interdisciplinary relationships. The SCI Institute has a long tradition of building these relationships in a win-win fashion – a win for the theoretical and algorithmic development of numerical modeling and simulation techniques and a win for the discipline-specific science of interest. High-order and adaptive methods, uncertainty quantification, complexity analysis, and parallelization are just some of the topics being investigated by SCI faculty. These areas of computing are being applied to a wide variety of engineering applications ranging from fluid mechanics and solid mechanics to bioelectricity.


Valerio Pascucci
Scientific Data Management
Chris Johnson
Problem Solving Environments
Ross Whitaker
GPUs
Chuck Hansen
GPUs
Funded Research Projects:
Publications in Scientific Computing:

|
  Efficient I/O and storage of adaptive-resolution data S. Kumar, J. Edwards, P.-T. Bremer, A. Knoll, C. Christensen, V. Vishwanath, P. Carns, J.A. Schmidt, V. Pascucci. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, pp. 413--423. 2014. DOI: 10.1109/SC.2014.39 We present an efficient, flexible, adaptive-resolution I/O framework that is suitable for both uniform and Adaptive Mesh Refinement (AMR) simulations. In an AMR setting, current solutions typically represent each resolution level as an independent grid which often results in inefficient storage and performance. Our technique coalesces domain data into a unified, multiresolution representation with fast, spatially aggregated I/O. Furthermore, our framework easily extends to importance-driven storage of uniform grids, for example, by storing regions of interest at full resolution and nonessential regions at lower resolution for visualization or analysis. Our framework, which is an extension of the PIDX framework, achieves state of the art disk usage and I/O performance regardless of resolution of the data, regions of interest, and the number of processes that generated the data. We demonstrate the scalability and efficiency of our framework using the Uintah and S3D large-scale combustion codes on the Mira and Edison supercomputers. |
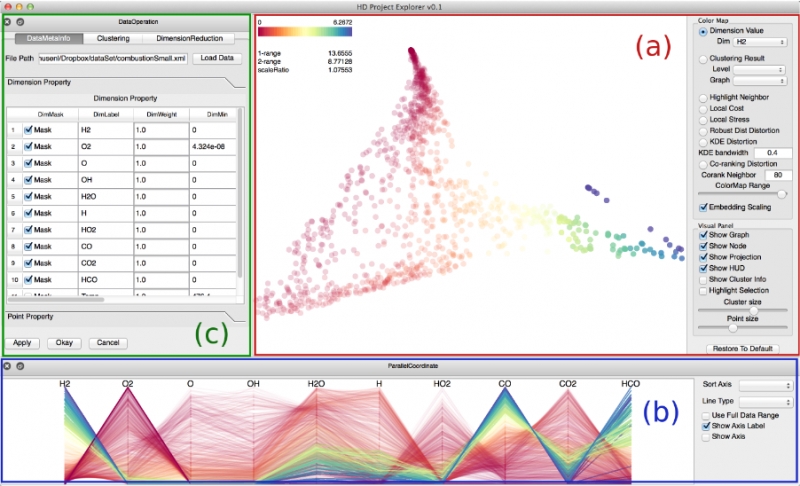
| Visual Exploration of High-Dimensional Data: Subspace Analysis through Dynamic Projections SCI Technical Report, Shusen Liu, Bei Wang, J.J. Thiagarajan, P.-T. Bremer, V. Pascucci. No. UUSCI-2014-003, SCI Institute, University of Utah, 2014. Understanding high-dimensional data is rapidly becoming a central challenge in many areas of science and engineering. Most current techniques either rely on manifold learning based techniques which typically create a single embedding of the data or on subspace selection to find subsets of the original attributes that highlight the structure. However, the former creates a single, difficult-to-interpret view and assumes the data to be drawn from a single manifold, while the latter is limited to axis-aligned projections with restrictive viewing angles. Instead, we introduce ideas based on subspace clustering that can faithfully represent more complex data than the axis-aligned projections, yet do not assume the data to lie on a single manifold. In particular, subspace clustering assumes that the data can be represented by a union of low-dimensional subspaces, which can subsequently be used for analysis and visualization. In this paper, we introduce new techniques to reliably estimate both the intrinsic dimension and the linear basis of a mixture of subspaces extracted through subspace clustering. We show that the resulting bases represent the high-dimensional structures more reliably than traditional approaches. Subsequently, we use the bases to define different “viewpoints”, i.e., different projections onto pairs of basis vectors, from which to visualize the data. While more intuitive than non-linear projections, interpreting linear subspaces in terms of the original dimensions can still be challenging. To address this problem, we present new, animated transitions between different views to help the user navigate and explore the high-dimensional space. More specifically, we introduce the view transition graph which contains nodes for each subspace viewpoint and edges for potential transition between views. The transition graph enables users to explore both the structure within a subspace and the relations between different subspaces, for better understanding of the data. Using a number of case studies on well-know reference datasets, we demonstrate that the interactive exploration through such dynamic projections provides additional insights not readily available from existing tools. Keywords: High-dimensional data, Subspace, Dynamic projection |
| Systematic Debugging of Concurrent Systems Using Coalesced Stack Trace Graphs D.C.B. de Oliveira, A. Humphrey, Q. Meng, Z. Rakamaric, M. Berzins, G. Gopalakrishnan. In Proceedings of the 27th International Workshop on Languages and Compilers for Parallel Computing (LCPC), September, 2014. A central need during software development of large-scale parallel systems is tools that help help to identify the root causes of bugs quickly. Given the massive scale of these systems, tools that highlight changes--say introduced across software versions or their operating conditions (e.g., inputs, schedules)--can prove to be highly effective in practice. Conventional debuggers, while good at presenting details at the problem-site (e.g., crash), often omit contextual information to identify the root causes of the bug. We present a new approach to collect and coalesce stack traces, leading to an efficient summary display of salient system control flow differences in a graphical form called Coalesced Stack Trace Graphs (CSTG). CSTGs have helped us understand and debug situations within a computational framework called Uintah that has been deployed at large scale, and undergoes frequent version updates. In this paper, we detail CSTGs through case studies in the context of Uintah where unexpected behaviors caused by different vesions of software or occurring across different time-steps of a system (e.g., due to non-determinism) are debugged. We show that CSTG also gives conventional debuggers a far more productive and guided role to play. |
|
Distortion-Guided Structure-Driven Interactive Exploration of High-Dimensional Data S. Liu, Bei Wang, P.-T. Bremer, V. Pascucci. In Computer Graphics Forum, Vol. 33, No. 3, Wiley-Blackwell, pp. 101--110. June, 2014. Dimension reduction techniques are essential for feature selection and feature extraction of complex high-dimensional data. These techniques, which construct low-dimensional representations of data, are typically geometrically motivated, computationally efficient and approximately preserve certain structural properties of the data. However, they are often used as black box solutions in data exploration and their results can be difficult to interpret. To assess the quality of these results, quality measures, such as co-ranking [ LV09 ], have been proposed to quantify structural distortions that occur between high-dimensional and low-dimensional data representations. Such measures could be evaluated and visualized point-wise to further highlight erroneous regions [ MLGH13 ]. In this work, we provide an interactive visualization framework for exploring high-dimensional data via its two-dimensional embeddings obtained from dimension reduction, using a rich set of user interactions. We ask the following question: what new insights do we obtain regarding the structure of the data, with interactive manipulations of its embeddings in the visual space? We augment the two-dimensional embeddings with structural abstrac- tions obtained from hierarchical clusterings, to help users navigate and manipulate subsets of the data. We use point-wise distortion measures to highlight interesting regions in the domain, and further to guide our selection of the appropriate level of clusterings that are aligned with the regions of interest. Under the static setting, point-wise distortions indicate the level of structural uncertainty within the embeddings. Under the dynamic setting, on-the-fly updates of point-wise distortions due to data movement and data deletion reflect structural relations among different parts of the data, which may lead to new and valuable insights. |
|
Analyzing Simulation-Based PRA Data Through Clustering: a BWR Station Blackout Case Study D. Maljovec, S. Liu, Bei Wang, V. Pascucci, P.-T. Bremer, D. Mandelli, C. Smith. In Proceedings of the Probabilistic Safety Assessment & Management conference (PSAM), 2014. Dynamic probabilistic risk assessment (DPRA) methodologies couple system simulator codes (e.g., RELAP, MELCOR) with simulation controller codes (e.g., RAVEN, ADAPT). Whereas system simulator codes accurately model system dynamics deterministically, simulation controller codes introduce both deterministic (e.g., system control logic, operating procedures) and stochastic (e.g., component failures, parameter uncertainties) elements into the simulation. Typically, a DPRA is performed by 1) sampling values of a set of parameters from the uncertainty space of interest (using the simulation controller codes), and 2) simulating the system behavior for that specific set of parameter values (using the system simulator codes). For complex systems, one of the major challenges in using DPRA methodologies is to analyze the large amount of information (i.e., large number of scenarios ) generated, where clustering techniques are typically employed to allow users to better organize and interpret the data. In this paper, we focus on the analysis of a nuclear simulation dataset that is part of the risk-informed safety margin characterization (RISMC) boiling water reactor (BWR) station blackout (SBO) case study. We apply a software tool that provides the domain experts with an interactive analysis and visualization environment for understanding the structures of such high-dimensional nuclear simulation datasets. Our tool encodes traditional and topology-based clustering techniques, where the latter partitions the data points into clusters based on their uniform gradient flow behavior. We demonstrate through our case study that both types of clustering techniques complement each other in bringing enhanced structural understanding of the data. Keywords: PRA, computational topology, clustering, high-dimensional analysis |

|
Systematic Debugging Methods for Large-Scale HPC Computational Frameworks A. Humphrey, Q. Meng, M. Berzins, D. Caminha B.de Oliveira, Z. Rakamaric, G. Gopalakrishnan. In Computing in Science Engineering, Vol. 16, No. 3, pp. 48--56. May, 2014. ISSN: 1521-9615 DOI: 10.1109/MCSE.2014.11 Parallel computational frameworks for high performance computing (HPC) are central to the advancement of simulation based studies in science and engineering. Unfortunately, finding and fixing bugs in these frameworks can be extremely time consuming. Left unchecked, these bugs can drastically diminish the amount of new science that can be performed. This paper presents our systematic study of the Uintah Computational Framework, and our approaches to debug it more incisively. Our key insight is to leverage the modular structure of Uintah which lends itself to systematic debugging. In particular, we have developed a new approach based on Coalesced Stack Trace Graphs (CSTGs) that summarize the system behavior in terms of key control flows manifested through function invocation chains. We illustrate several scenarios how CSTGs could help efficiently localize bugs, and present a case study of how we found and fixed a real Uintah bug using CSTGs. Keywords: Computational Modeling and Frameworks, Parallel Programming, Reliability, Debugging Aids |
| ASCAC Workforce Subcommittee Letter B. Chapman, H. Calandra, S. Crivelli, J. Dongarra, J. Hittinger, C.R. Johnson, S.A. Lathrop, V. Sarkar, E. Stahlberg, J.S. Vetter, D. Williams. Note: Office of Scientific and Technical Information, DOE ASCAC Committee Report, July, 2014. DOI: 10.2172/1222711 Simulation and computing are essential to much of the research conducted at the DOE national laboratories. Experts in the ASCR-relevant Computing Sciences, which encompass a range of disciplines including Computer Science, Applied Mathematics, Statistics and domain sciences, are an essential element of the workforce in nearly all of the DOE national laboratories. This report seeks to identify the gaps and challenges facing DOE with respect to this workforce. |
| A survey of high level frameworks in block-structured adaptive mesh refinement packages A. Dubey, A. Almgren, John Bell, M. Berzins, S. Brandt, G. Bryan, P. Colella, D. Graves, M. Lijewski, F. Löffler, B. O’Shea, E. Schnetter, B. Van Straalen, K. Weide. In Journal of Parallel and Distributed Computing, 2014. DOI: 10.1016/j.jpdc.2014.07.001 Over the last decade block-structured adaptive mesh refinement (SAMR) has found increasing use in large, publicly available codes and frameworks. SAMR frameworks have evolved along different paths. Some have stayed focused on specific domain areas, others have pursued a more general functionality, providing the building blocks for a larger variety of applications. In this survey paper we examine a representative set of SAMR packages and SAMR-based codes that have been in existence for half a decade or more, have a reasonably sized and active user base outside of their home institutions, and are publicly available. The set consists of a mix of SAMR packages and application codes that cover a broad range of scientific domains. We look at their high-level frameworks, their design trade-offs and their approach to dealing with the advent of radical changes in hardware architecture. The codes included in this survey are BoxLib, Cactus, Chombo, Enzo, FLASH, and Uintah. Keywords: SAMR, BoxLib, Chombo, FLASH, Cactus, Enzo, Uintah |
| Parallel Breadth First Search on GPU Clusters SCI Technical Report, Z. Fu, H.K. Dasari, M. Berzins, B. Thompson. No. UUSCI-2014-002, SCI Institute, University of Utah, 2014. Fast, scalable, low-cost, and low-power execution of parallel graph algorithms is important for a wide variety of commercial and public sector applications. Breadth First Search (BFS) imposes an extreme burden on memory bandwidth and network communications and has been proposed as a benchmark that may be used to evaluate current and future parallel computers. Hardware trends and manufacturing limits strongly imply that many core devices, such as NVIDIA® GPUs and the Intel® Xeon Phi®, will become central components of such future systems. GPUs are well known to deliver the highest FLOPS/watt and enjoy a very significant memory bandwidth advantage over CPU architectures. Recent work has demonstrated that GPUs can deliver high performance for parallel graph algorithms and, further, that it is possible to encapsulate that capability in a manner that hides the low level details of the GPU architecture and the CUDA language but preserves the high throughput of the GPU. We extend previous research on GPUs and on scalable graph processing on super-computers and demonstrate that a high-performance parallel graph machine can be created using commodity GPUs and networking hardware. Keywords: GPU cluster, MPI, BFS, graph, parallel graph algorithm |

|
Fast Multi-Resolution Reads of Massive Simulation Datasets S. Kumar, C. Christensen, P.-T. Bremer, E. Brugger, V. Pascucci, J. Schmidt, M. Berzins, H. Kolla, J. Chen, V. Vishwanath, P. Carns, R. Grout. In Proceedings of the International Supercomputing Conference ISC'14, Leipzig, Germany, June, 2014. Today's massively parallel simulation code can produce output ranging up to many terabytes of data. Utilizing this data to support scientific inquiry requires analysis and visualization, yet the sheer size of the data makes it cumbersome or impossible to read without computational resources similar to the original simulation. We identify two broad classes of problems for reading data and present effective solutions for both. The first class of data reads depends on user requirements and available resources. Tasks such as visualization and user-guided analysis may be accomplished using only a subset of variables with restricted spatial extents at a reduced resolution. The other class of reads require full resolution multi-variate data to be loaded, for example to restart a simulation. We show that utilizing the hierarchical multi-resolution IDX data format enables scalable and efficient serial and parallel read access on a variety of hardware from supercomputers down to portable devices. We demonstrate interactive view-dependent visualization and analysis of massive scientific datasets using low-power commodity hardware, and we compare read performance with other parallel file formats for both full and partial resolution data. |
| Scalable large-scale fluid-structure interaction solvers in the Uintah framework via hybrid task-based parallelism algorithms Q. Meng, M. Berzins. In Concurrency and Computation: Practice and Experience, Vol. 26, No. 7, pp. 1388--1407. May, 2014. DOI: 10.1002/cpe Uintah is a software framework that provides an environment for solving fluid–structure interaction problems on structured adaptive grids for large-scale science and engineering problems involving the solution of partial differential equations. Uintah uses a combination of fluid flow solvers and particle-based methods for solids, together with adaptive meshing and a novel asynchronous task-based approach with fully automated load balancing. When applying Uintah to fluid–structure interaction problems, the combination of adaptive mesh- ing and the movement of structures through space present a formidable challenge in terms of achieving scalability on large-scale parallel computers. The Uintah approach to the growth of the number of core counts per socket together with the prospect of less memory per core is to adopt a model that uses MPI to communicate between nodes and a shared memory model on-node so as to achieve scalability on large-scale systems. For this approach to be successful, it is necessary to design data structures that large numbers of cores can simultaneously access without contention. This scalability challenge is addressed here for Uintah, by the development of new hybrid runtime and scheduling algorithms combined with novel lock-free data structures, making it possible for Uintah to achieve excellent scalability for a challenging fluid–structure problem with mesh refinement on as many as 260K cores. Keywords: MPI, threads, Uintah, many core, lock free, fluid-structure interaction, c-safe |
|
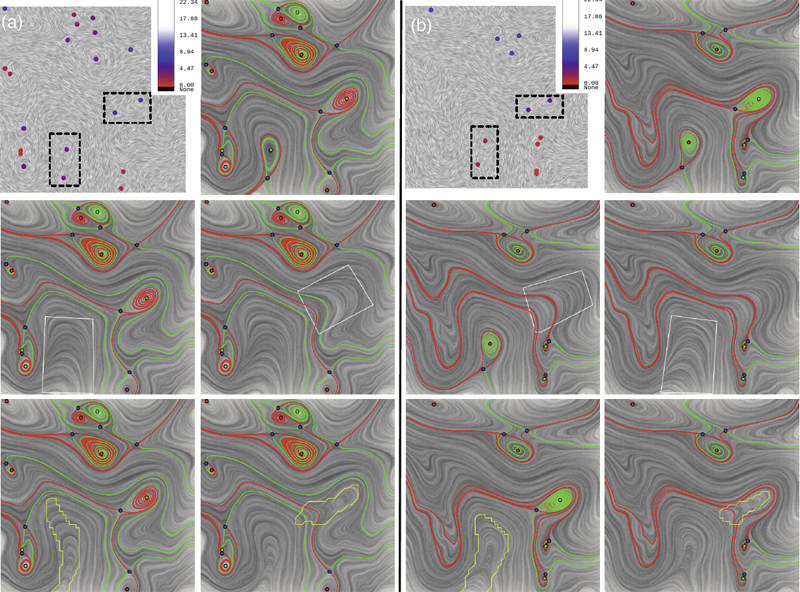
An Alternative Formulation of Lyapunov Exponents for Computing Lagrangian Coherent Structures A.R. Sanderson. In Proceedings of the 2014 IEEE Pacific Visualization Symposium (PacificVis), Yokahama Japan, 2014. Lagrangian coherent structures are time-evolving surfaces that highlight areas in flow fields where neighboring advected particles diverge or converge. The detection and understanding of such structures is an important part of many applications such as in oceanography where there is a need to predict the dispersion of oil and other materials in the ocean. One of the most widely used tools for revealing Lagrangian coherent structures has been to calculate the finite-time Lyapunov exponents, whose maximal values appear as ridgelines to reveal Lagrangian coherent structures. In this paper we explore an alternative formulation of Lyapunov exponents for computing Lagrangian coherent structures. |
| Geometric constraints on quadratic Bézier curves using minimal length and energy Y. Joon Ahn, C. Hoffmann, P. Rosen. In Journal of Computational and Applied Mathematics, Vol. 255, pp. 887--897. 2014. This paper derives expressions for the arc length and the bending energy of quadratic Bézier curves. The formulas are in terms of the control point coordinates. For fixed start and end points of the Bézier curve, the locus of the middle control point is analyzed for curves of fixed arc length or bending energy. In the case of arc length this locus is convex. For bending energy it is not. Given a line or a circle and fixed end points, the locus of the middle control point is determined for those curves that are tangent to a given line or circle. For line tangency, this locus is a parallel line. In the case of the circle, the locus can be classified into one of six major types. In some of these cases, the locus contains circular arcs. These results are then used to implement fast algorithms that construct quadratic Bézier curves tangent to a given line or circle, with given end points, that minimize bending energy or arc length. |
|
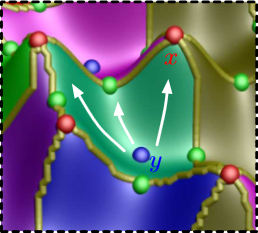
2D Vector Field Simplification Based on Robustness P. Skraba, Bei Wang, G. Chen, P. Rosen. In Proceedings of the 2014 IEEE Pacific Visualization Symposium, PacificVis, Note: Awarded Best Paper!, 2014. Vector field simplification aims to reduce the complexity of the flow by removing features in order of their relevance and importance, to reveal prominent behavior and obtain a compact representation for interpretation. Most existing simplification techniques based on the topological skeleton successively remove pairs of critical points connected by separatrices, using distance or area-based relevance measures. These methods rely on the stable extraction of the topological skeleton, which can be difficult due to instability in numerical integration, especially when processing highly rotational flows. These geometric metrics do not consider the flow magnitude, an important physical property of the flow. In this paper, we propose a novel simplification scheme derived from the recently introduced topological notion of robustness, which provides a complementary view on flow structure compared to the traditional topological-skeleton-based approaches. Robustness enables the pruning of sets of critical points according to a quantitative measure of their stability, that is, the minimum amount of vector field perturbation required to remove them. This leads to a hierarchical simplification scheme that encodes flow magnitude in its perturbation metric. Our novel simplification algorithm is based on degree theory, has fewer boundary restrictions, and so can handle more general cases. Finally, we provide an implementation under the piecewise-linear setting and apply it to both synthetic and real-world datasets. Keywords: vector field, topology-based techniques, flow visualization |
International Journal for Uncertainty Quantification, Subtitled “Special Issue on Working with Uncertainty: Representation, Quantification, Propagation, Visualization, and Communication of Uncertainty,” C.R. Johnson, A. Pang (Eds.). In Int. J. Uncertainty Quantification, Vol. 3, No. 3, Begell House, Inc., 2013. ISSN: 2152-5080 DOI: 10.1615/Int.J.UncertaintyQuantification.v3.i3 |
International Journal for Uncertainty Quantification, Subtitled “Special Issue on Working with Uncertainty: Representation, Quantification, Propagation, Visualization, and Communication of Uncertainty,” C.R. Johnson, A. Pang (Eds.). In Int. J. Uncertainty Quantification, Vol. 3, No. 2, Begell House, Inc., pp. vii--viii. 2013. ISSN: 2152-5080 DOI: 10.1615/Int.J.UncertaintyQuantification.v3.i2 |

|
A Fast Iterative Method for Solving the Eikonal Equation on Tetrahedral Domains Z. Fu, R.M. Kirby, R.T. Whitaker. In SIAM Journal on Scientific Computing, Vol. 35, No. 5, pp. C473--C494. 2013. Generating numerical solutions to the eikonal equation and its many variations has a broad range of applications in both the natural and computational sciences. Efficient solvers on cutting-edge, parallel architectures require new algorithms that may not be theoretically optimal, but that are designed to allow asynchronous solution updates and have limited memory access patterns. This paper presents a parallel algorithm for solving the eikonal equation on fully unstructured tetrahedral meshes. The method is appropriate for the type of fine-grained parallelism found on modern massively-SIMD architectures such as graphics processors and takes into account the particular constraints and capabilities of these computing platforms. This work builds on previous work for solving these equations on triangle meshes; in this paper we adapt and extend previous 2D strategies to accommodate three-dimensional, unstructured, tetrahedralized domains. These new developments include a local update strategy with data compaction for tetrahedral meshes that provides solutions on both serial and parallel architectures, with a generalization to inhomogeneous, anisotropic speed functions. We also propose two new update schemes, specialized to mitigate the natural data increase observed when moving to three dimensions, and the data structures necessary for efficiently mapping data to parallel SIMD processors in a way that maintains computational density. Finally, we present descriptions of the implementations for a single CPU, as well as multicore CPUs with shared memory and SIMD architectures, with comparative results against state-of-the-art eikonal solvers. |

|
Scalable Visualization and Interactive Analysis Using Massive Data Streams V. Pascucci, P.-T. Bremer, A. Gyulassy, G. Scorzelli, C. Christensen, B. Summa, S. Kumar. In Cloud Computing and Big Data, Advances in Parallel Computing, Vol. 23, IOS Press, pp. 212--230. 2013. Historically, data creation and storage has always outpaced the infrastructure for its movement and utilization. This trend is increasing now more than ever, with the ever growing size of scientific simulations, increased resolution of sensors, and large mosaic images. Effective exploration of massive scientific models demands the combination of data management, analysis, and visualization techniques, working together in an interactive setting. The ViSUS application framework has been designed as an environment that allows the interactive exploration and analysis of massive scientific models in a cache-oblivious, hardware-agnostic manner, enabling processing and visualization of possibly geographically distributed data using many kinds of devices and platforms. For general purpose feature segmentation and exploration we discuss a new paradigm based on topological analysis. This approach enables the extraction of summaries of features present in the data through abstract models that are orders of magnitude smaller than the raw data, providing enough information to support general queries and perform a wide range of analyses without access to the original data. Keywords: Visualization, data analysis, topological data analysis, Parallel I/O |
|
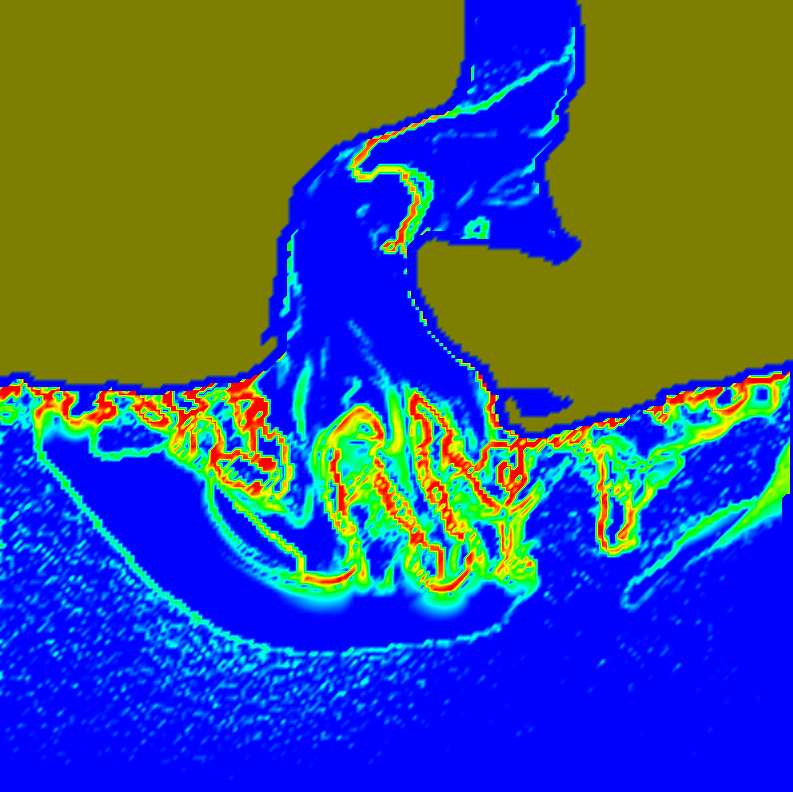
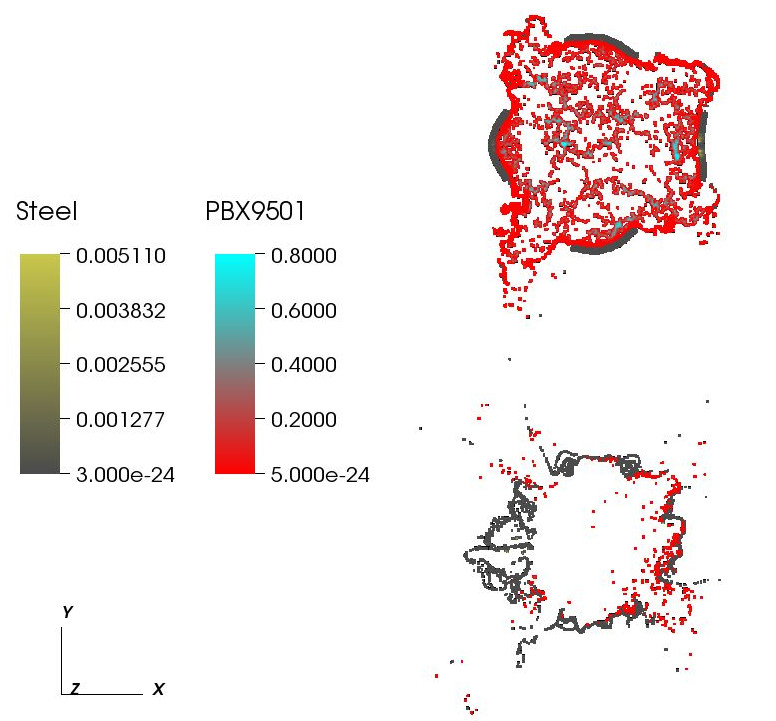
The influence of an applied heat flux on the violence of reaction of an explosive device M. Hall, J.C. Beckvermit, C.A. Wight, T. Harman, M. Berzins. In Proceedings of the Conference on Extreme Science and Engineering Discovery Environment: Gateway to Discovery, San Diego, California, XSEDE '13, pp. 11:1--11:8. 2013. ISBN: 978-1-4503-2170-9 DOI: 10.1145/2484762.2484786 It is well known that the violence of slow cook-off explosions can greatly exceed the comparatively mild case burst events typically observed for rapid heating. However, there have been few studies that examine the reaction violence as a function of applied heat flux that explore the dependence on heating geometry and device size. Here we report progress on a study using the Uintah Computation Framework, a high-performance computer model capable of modeling deflagration, material damage, deflagration to detonation transition and detonation for PBX9501 and similar explosives. Our results suggests the existence of a sharp threshold for increased reaction violence with decreasing heat flux. The critical heat flux was seen to increase with increasing device size and decrease with the heating of multiple surfaces, suggesting that the temperature gradient in the heated energetic material plays an important role the violence of reactions. Keywords: DDT, cook-off, deflagration, detonation, violence of reaction, c-safe |
| Characterization and modeling of PIDX parallel I/O for performance optimization S. Kumar, A. Saha, V. Vishwanath, P. Carns, J.A. Schmidt, G. Scorzelli, H. Kolla, R. Grout, R. Latham, R. Ross, M.E. Papka, J. Chen, V. Pascucci. In Proceedings of SC13: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 67. 2013. Parallel I/O library performance can vary greatly in response to user-tunable parameter values such as aggregator count, file count, and aggregation strategy. Unfortunately, manual selection of these values is time consuming and dependent on characteristics of the target machine, the underlying file system, and the dataset itself. Some characteristics, such as the amount of memory per core, can also impose hard constraints on the range of viable parameter values. In this work we address these problems by using machine learning techniques to model the performance of the PIDX parallel I/O library and select appropriate tunable parameter values. We characterize both the network and I/O phases of PIDX on a Cray XE6 as well as an IBM Blue Gene/P system. We use the results of this study to develop a machine learning model for parameter space exploration and performance prediction. Keywords: I/O, Network Characterization, Performance Modeling |